1. Introduction
The explosion of information in the modern environment demands the ability to collect, organize, manage, and search large amounts of information across a wide variety of real-world applications. The primary tools available for such tasks are large-scale database systems and keyword-based document search techniques. However, such tools are rapidly proving inadequate: traditional database systems do not enable ready access to relevant knowledge, prompting a market of add-ons [8] and existing search techniques are insufficiently precise or selective to support such tasks, leading to consumer exasperation [10, 14, 17, 18, 20]. In the end users are left unsatisfied, confronted with a sea of unorganized and unhelpful data. A new approach is needed.
The Information Research Intelligent Assistant (IRIA) is an integrated information retrieval architecture that addresses this problem. IRIA enables a user or workgroup to build a personalized map of the relevant information available in a database, intranet, or internet, and the ability to find, add, and use information quickly and easily. An IRIA-based intelligent information management system acts as an autonomous assistant to a user working on a task, working unobtrusively in the background to learn both the user’s interests and the resources available to satisfy those interests. This approach enables “reminding engines” which monitor a user’s work to proactively find and recommend useful information as well as “workgroup memories” which learn from a user’s behavior to build a comprehensive knowledge map of a particular area of interest.
In empirical tests, IRIA has demonstrated the ability to monitor a user's progress on a task (specifically, web search) and proactively find and recommend information relevant to that task based on the context and history of the user’s interactions with the system. IRIA further demonstrated that it could provide collaborative facilities to the workgroup and that it could learn and improve its knowledge map over time.
2. The Approach
To model the interests, needs and knowledge of individuals and workgroups, IRIA applies experience-based agency to the problem of information search. Experience-based agency is a cognitive science approach to the problem of managing information access to large knowledge bases [19]. Inspired by research in human memory and expert performance, the experience-based agent approach outlines how to construct a reasoning system based on a context-sensitive asynchronous memory. It specifies not only an algorithm for context sensitive asynchronous memory but also knowledge representation, working memory and task control systems which work with that memory, along with a specification of how to construct reasoning tasks that exploit that memory. The goal of the experience-based agent approach is to provide technologies and guidelines for the construction of complete autonomous and semi-autonomous programs operating in task environments for the assistance of human users.
The IRIA architecture builds upon and extends the experience-based agent approach by embedding it in a knowledge discovery and presentation engine using techniques from artificial intelligence and machine learning. Crushing demands on resources limit the amount of “smarts” typical web search engines can apply to any particular information resource requests. IRIA’s design overcomes this problem by leveraging existing search engines for the brute force work of indexing and searching the web and by focusing its “smarts” on modeling and understanding the efforts of an individual or workgroup.
The core of IRIA that makes this understanding possible is its reminding engine. The reminding engine directly applies the experience-based agent approach to the problem of information search, consisting of a context-sensitive search mediator which uses a unified semantic knowledge base called a knowledge map to represent indexed pages, queries, and even browsing sessions in a single format. This uniform representation enables the development of an experience-based map of available information resources, along with judgments about their relevance, allowing precise searches based on the history of research for an individual, group or online community. The knowledge map is furthermore a browsable information resource in its own right, accessible by standard internetworking protocols; with appropriate security precautions, this enables workgroups at remote sites to view and exploit information collected by another workgroup.
3. Results
To evaluate the approach we developed a prototype of IRIA focused on information search application. The prototype is deployed as an extension to the CL-HTTP web server [16] and accessed through a browser-based interface. The prototype uses a metasearch system to execute a query on existing Web search engines (e.g., Altavista, Yahoo, etc.) and then summarizes the returned hits into a knowledge map. The prototype application displays search results on the left and the user’s current selected result in the center. As the user browses, IRIA is reminded of pages and displays these dynamically computed results on the right, enabling users to quickly focus on relevant results (Figure 1).
3.1. Supporting Individuals
Our first evaluations tested how effective IRIA was at recommending useful information to users. The evaluation modeled a user with a specific need for information entering an ambiguous query and receiving a large number of results, which the user then begins to browse in search of relevant information. Our hypothesis was that if a user selected initial pages relevant to their desired category, IRIA would be able to provide other pages relevant to that category and speed the user’s search. Our prediction was that with each user click, the number of pages in IRIA’s Top 10 or Top 20 list relevant to the user’s category would increase until the proportion was significantly better than chance.
We collected two data sets for controlled offline search, including one generic search from AltaVista on “dolphin”(s) and one special-purpose search of job postings. Our hypothesis was that if a user selected pages relevant to, say, dolphin vacations or dolphin cognition, IRIA would be able to quickly provide recommendations of other relevant pages, thus reducing the need for the user to wade through overwhelming numbers of results.
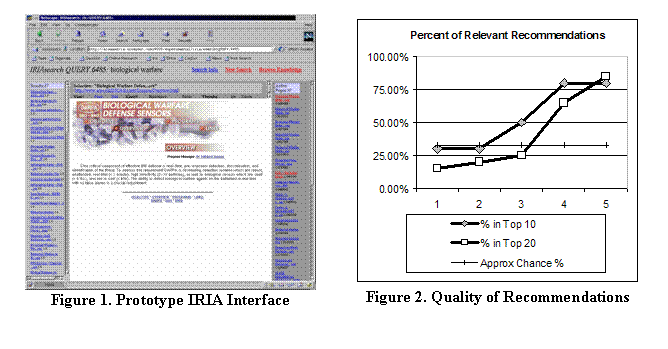
On both data sets and in all three conditions, IRIA presented a proportion of
relevant results relevant greater than chance after only one to three
selections by the user. In certain conditions on the dolphin data set, IRIA
produced 90-100% relevant recommendations; on the job posting data set IRIA was
still able to produce 60%-80% relevant results within a few user clicks. One
sample set of results from the “dolphin” data set are displayed in Figure 2.
3.2. Supporting an Workgroup
We also simulated a workgroup situation with two independent users seated at different workstations searching for different types of information on the web. The system was able to develop a knowledge map of both types of information and suggest pages that were of relevance to the workgroup. As one example, with one user searching for and browsing through information on the middle east and another searching for and browsing through information on biological warfare (Figure 1), IRIA found and recommended a page from a political analyst discussing whether Iraq might still have biological weapons. IRIA's knowledge map also contained information about why this page was recommended; this can be used in future versions to provide users with an explanation of the system's reasoning if desired.
3.3. Discussion
In summary, our initial empirical results demonstrate that context-sensitive search is a feasible technology for managing information needs in a database, intranet, or internet application. Qualitative user evaluations also provided strong positive feedback about the use of semantic maps for storing knowledge and sharing it across workgroups. Together, these results demonstrate the feasibility of the IRIA technology for intelligent information management.
4. Related Work
IRIA builds on much of the pioneering work in information retrieval on the Internet. For example, the knowledge map builds on existing approaches to cataloging information resources, such as web search indices like Alta Vista, Lycos and Web Crawler [1, 4], web directories like Yahoo [21], information resource mapping systems such as Harvest and Desire [2, 3] and search ontologies as used in Ariadne [13] and InfoSleuth [11]. The knowledge map goes beyond these approaches by unifying indexing with a writable information space in which a user or workgroup can annotate and update descriptions of known information resources.
IRIA’s asynchronous search extends the incremental web search approach pioneered by systems like the early versions of Lycos [4] by reifying user queries as explicit semantic knowledge objects; this supports the novel capability to retrieve “best-guess” retrieval of pages while the queries are being processed in the background, as well as allowing the explicit manipulation of query properties during incremental search. IRIA’s context-sensitive web search extends the browsing aid approach pioneered by such systems as Fish [5] and WebWatcher [12] by using feedback from the user’s browsing to aid ongoing asynchronous searches in addition to aiding browsing itself.
Finally, the search mediation engine used by IRIA applies a harvesting or metasearch approach similar to Harvest [3] the MetaCrawler [6] and SavvySearch [9] but differs in that the rich structure of the knowledge map permits the direct browsing of the database of pages.
5. Future Work
The results of the first phase of the IRIA project demonstrated the technical feasibility of the approach. Scaling this technology up to user applications raises a new set of technical challenges.
5.1. Secure Knowledge Representations
Traditional AI techniques for knowledge representation are designed to recreate in a computer the conditions inside a single human mind — an environment in which security concerns are not an issue. Because IRIA’s knowledge maps will be accessible to many users and workgroups or even the entire Internet, security is a significant concern. A technical challenge will be to augment traditional AI knowledge representation used in IRIA with security features sufficient to control the dissemination of knowledge to appropriate personnel.
5.2. Data Integrity Issues
Traditional AI techniques for knowledge representation are not designed for a robust work environment — typically AI systems use large monolithic knowledge bases with little support for persistence, distribution, and transaction processing. The technical challenge in this area will be to augment the traditional AI knowledge representation used in IRIA with persistence and storage features designed to enhance its ability to operate in a production environment.
5.3. Advances in Context Sensitivity
While our initial effort demonstrated the feasibility of the IRIA context-sensitive search technology, delivering a majority of relevant results with only a few pieces of data from a user, this technology could continue to be improved. While producing 100% relevant results before the user asks a question is not technically feasible at this time, it nonetheless remains a worthy goal to create the illusion of omniscience. Relevant techniques include better context sensitive search algorithms, learning user profiles, tracking group interests, and so on.
5.4. Content Theories for Applications
Another important area of research is the development of “content theories” for potential application domains. The knowledge representation used in IRIA, while sufficient to provide solid results, can be continuously and incrementally extended to enable more precise searches and recommendations. If a particular application domain is specified, then IRIA’s knowledge representation can be extended with a content theory of the domain that incorporates both the additional structure of documents in the domain and rules that exploit that structure to improve retrieval. We have already explored the application of IRIA to problem-based learning in science education.
These technical challenges must be considered hand in hand with the more traditional software engineering challenges of scaling up the IRIA research prototype into a full-fledged information toolkit which can be used in production environments.
Acknowledgements
This work was conducted at Enkia Corporation with the support of Air Force Rome Labs under SBIR program contract F30602-99-C-0095, with the support of the Department of Education under SBIR RFP ED-99-Q-0002, and with the support of the Georgia Institute of Technology.
References
[1] Altavista. 1999. www.altavista.com
[2] Ardö, A., & Lundberg, S. 199?. A regional distributed WWW search and indexing service – the DESIRE way. http://nwi.dtv.dk/www7/; also see http://www.lub.lu.se/desire/
[3] Bowman, C. M., Danzig, P.B., Hardy, D. R., Manber, U., & Schwartz, M.F. 1994. The Harvest information discovery and access system. Proceedings of the Second International World Wide Web Conference, pp. 763-771, Chicago, Illinois, October 1994.
[4] Cheong, F. 1996. Internet agents: spiders, wanderers, brokers, and bots. New Riders.
[5] De Bra, P.M.E. & Post, R.D.J. 1994. Searching for arbitrary information in the WWW: the Fish-search for Mosaic. Proc. 2nd. Int. World Wide Web Conf., 1994.
[6] Etzioni, O. 1997. Moving up the information food chain: deploying softbots on the World Wide Web. AI Magazine, Summer 1997, pp. 11-18.
[7] Francis, A. & Ram, A. (1997). Can your architecture do this: A proposal for impasse-driven asynchronous memory retrieval request generation. In Proceedings of the AAAI-97 Workshop on ROBOTS, SOFTBOTS, IMMOBOTS: Theories of Action, Planning and Control.
[8] Green, H. (1999) The Information Gold Mine. Business Week e.biz, July 26 1999, pp. EB17-30
[9] Howe, A.E. & Dreilinger, D. 1997. SavvySearch: A metasearch engine which learns which search engines to query. AI Magazine, Summer 1997, pp. 19-25.
[10] Internet World (1998). Getting there, or not: Why search is so ineffective. Internet World Online Edition, February 23, 1998.
[11] Jacobs, N. & Shea, R. 1996. The role of Java in InfoSleuth: agent-based exploitation of heterogeneous information resources, IntraNet96 Java Developers Conference, April 1996.
[12] Joachims, T., Feitag, D., Mitchell, T. 1997. WebWatcher: a tour guide for the World Wide Web. Proceedings of IJCAI97, August 1997.
[13] Knoblock, C. A., Minton, S., Ambite, J.L., Ashish, N., Modi, P.J., Muslea, I., Philpot, A.G., Tejada, S. (1997) Modeling web sources for information integration. Proceedings of the Fifteenth National Conference on Artificial Intelligence, Madison, WI 1998.
[14] Lawrence, S. & Giles, C.L. (1999). Accessibility of information on the web.
[15] Lenat, D.B. and Guha, R.V. (1990). Building Large Knowledge-Based Systems: Representation and Inference in the Cyc Project. Addison-Wesley Publishing Company, Inc., 1990.
[16] Mallery, J.C. 1994. A Common LISP hypermedia server. Proceedings of the First International Conference on the World-Wide Web, Geneva: CERN, May 25, 1994.
[17] McWilliams, B. 1998. Search engine to sell top positions on results lists. PC World Online, February 23, 1998. http://www2.pcworld.com/news/daily/0298/9802233173204.html
[18] Pitta, J. (1999). !&#$%.com. Forbes, August 23, 1999, pp76-77.
[19] Ram, A., & Francis, A. G. 1996. Multi-Plan Retrieval and Adaptation in an Experience-Based Agent, In D. B. Leake, editor, Case-Based Reasoning: Experiences, Lessons, and Future Directions, AAAI Press.
[20] Riggs, B. (1999) Knowledge finders. Information Week, May 24, 1999.
[21] Yahoo. www.yahoo.com