
Yesterday I claimed that Christianity was following Jesus - looking at him as a role model for thinking, judging, and doing, stepping away from rules and towards principles, choosing good outcomes over bad ones and treating others like we wanted to be treated, and ultimately emulating what Jesus would do.
But it's an entirely fair question to ask, why do we need a role model to follow? Why not have a set of rules that guide our behavior, or develop good principles to live by? Well, it turns out it's impossible - not hard, but literally mathematically impossible - to have perfect rules, and principles do not guide actions. So a role model is the best tool we have to help us build the cognitive skill of doing the right thing.
Let's back up a bit. I want to talk about what rules are, and how they differ from principles and models.
In the jargon of my field, artificial intelligence, rules are if-then statements: if this, then do that. They map a range of propositions to a domain of outcomes, which might be actions, new propositions, or edits to our thoughts. There's a lot of evidence that the lower levels of operation of our minds is rule-like.
Principles, in contrast, are descriptions of situations. They don't prescribe what to do; they evaluate what has been done. The venerable artificial intelligence technique of generate-and-test - throw stuff on the wall to see what sticks - depends on "principles" to evaluate whether the outcomes are good.
Models are neither if-then rules nor principles. Models predict the evolution of a situation. Every time you play a computer game, a model predicts how the world will react to your actions. Every time you think to yourself, "I know what my friend would say in response to this", you're using a model.
Rules, of a sort, may underly our thinking, and some of our most important moral precepts are encoded in rules, like the Ten Commandments. But rules are fundamentally limited. No matter how attached you are to any given set of rules, eventually, those rules can fail you, and you can't know when.
The iron laws behind these fatal flaws are Gödel's incompleteness theorems. Back in the 1930's, Kurt Gödel showed any set of rules sophisticated enough to handle basic math would either fail to find things that were true, or would make mistakes - and, worse, could never prove that they were consistent.
Like so many seemingly abstract mathematical concepts, this has practical real-world implications. If you're dealing with anything at all complicated, and try to solve your problems with a set of rules, either those rules will fail to find the right answers, or will give the wrong answers, and you can't tell which.
That's why principles are better than rules: they make no pretensions of being a complete set of if-then rules that can handle all of arithmetic and their own job besides. They evaluate propositions, rather than generating them, they're not vulnerable to the incompleteness result in the same way.
How does this affect the moral teachings of religion? Well, think of it this way: God gave us the Ten Commandments (and much more) in the Old Testament, but these if-then rules needed to be elaborated and refined into a complete system. This was a cottage industry by the time Jesus came on the scene.
Breaking with the rule-based tradition, Jesus gave us principles, such as "love thy neighbor as thyself" and "forgive as you wish to be forgiven" which can be used to evaluate our actions. Sometimes, some thought is required to apply them, as in the case of "Is it lawful to do good or evil on the Sabbath?"
This is where principles fail: they don't generate actions, they merely evaluate them. Some other process needs to generate those actions. It could be a formal set of rules, but then we're back at square Gödel. It could be a random number generator, but an infinite set of monkeys will take forever to cross the street.
This is why Jesus's function as a role model - and the stories about Him in the Bible - are so important to Christianity. Humans generate mental models of other humans all the time. Once you've seen enough examples of someone's behavior, you can predict what they will do, and act and react accordingly.
The stories the Bible tells about Jesus facing moral questions, ethical challenges, physical suffering, and even temptation help us build a model of what Jesus would do. A good model of Jesus is more powerful than any rule and more useful than any principle: it is generative, easy to follow, and always applicable.
Even if you're not a Christian, this model of ethics can help you. No set of rules can be complete and consistent, or even fully checkable: rules lawyering is a dead end. Ethical growth requires moving beyond easy rules to broader principles which can be used to evaluate the outcomes of your choices.
But principles are not a guide to action. That's where role models come in: in a kind of imitation-based learning, they can help guide us by example until we've developed the cognitive skills to make good decisions automatically. Finding role models that you trust can help you grow, and not just morally.
Good role models can help you decide what to do in any situation. Not every question is relevant to the situations Jesus faced in ancient Galilee! For example, when faced with a conundrum, I sometimes ask three questions: "What would Jesus do? What would Richard Feynman do? What would Ayn Rand do?"
These role models seem far apart - Ayn Rand, in particular, tried to put herself on the opposite pole from Jesus. But each brings unique mental thought processes to the table - "Is this doing good or evil?" "You are the easiest person for yourself to fool" and "You cannot fake reality in any way whatsoever."
Jesus helps me focus on what choices are right. Feynman helps me challenge my assumptions and provides methods to test them. Rand is benevolent, but demands that we be honest about reality. If two or three of these role models agree on a course of action, it's probably a good choice.
Jesus was a real person in a distant part of history. We can only reach an understanding of who Jesus is and what He would do by reading the primary source materials about him - the Bible - and by analyses that help put these stories in context, like religious teachings, church tradition, and the use of reason.
But that can help us ask what Jesus would do. Learning the rules are important, and graduating beyond them to understand principles is even more important. But at the end of the day, we want to do the right thing, by following the lead of the man who asks, "Love thy neighbor as thyself."
-the Centaur
Pictured: Kurt Gödel, of course.







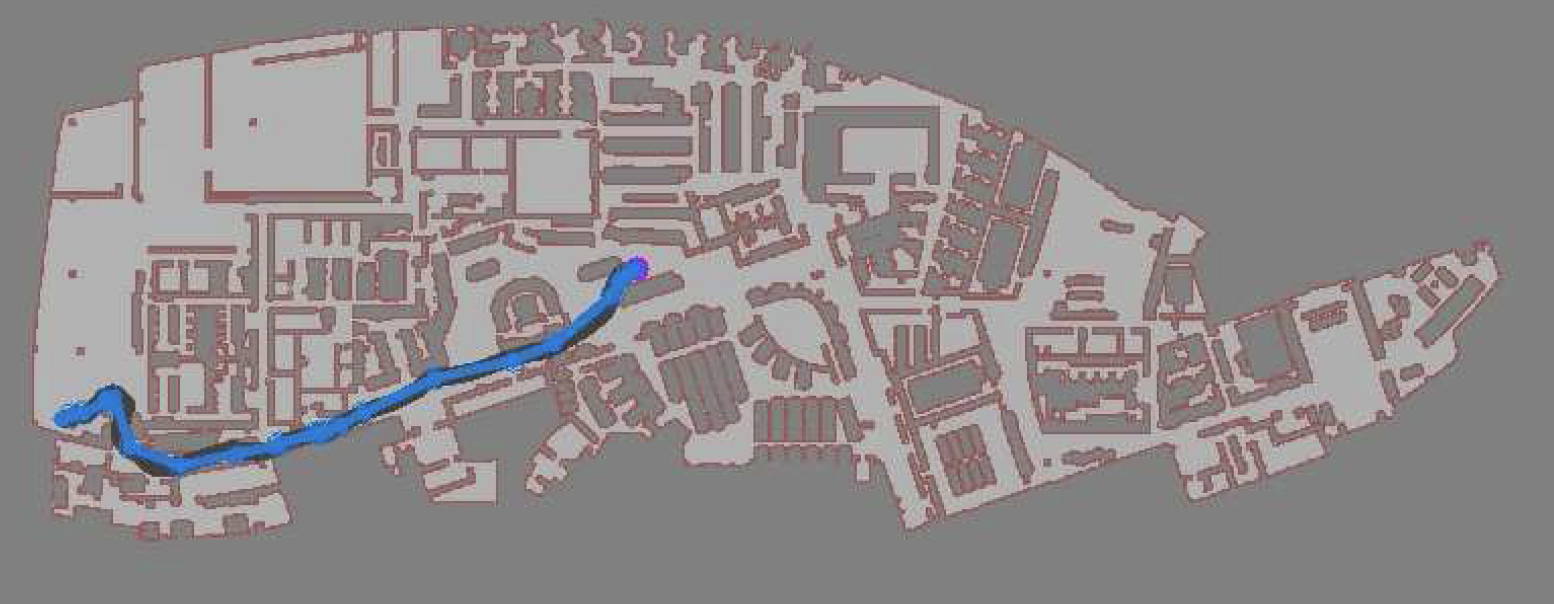
 So, this happened! Our team's paper on "PRM-RL" - a way to teach robots to navigate their worlds which combines human-designed algorithms that use roadmaps with deep-learned algorithms to control the robot itself - won a best paper award at the ICRA robotics conference!
So, this happened! Our team's paper on "PRM-RL" - a way to teach robots to navigate their worlds which combines human-designed algorithms that use roadmaps with deep-learned algorithms to control the robot itself - won a best paper award at the ICRA robotics conference!
 We were cited not just for this technique, but for testing it extensively in simulation and on two different kinds of robots. I want to thank everyone on the team - especially Sandra Faust for her background in PRMs and for taking point on the idea (and doing all the quadrotor work with Lydia Tapia), for Oscar Ramirez and Marek Fiser for their work on our reinforcement learning framework and simulator, for Kenneth Oslund for his heroic last-minute push to collect the indoor robot navigation data, and to our manager James for his guidance, contributions to the paper and support of our navigation work.
We were cited not just for this technique, but for testing it extensively in simulation and on two different kinds of robots. I want to thank everyone on the team - especially Sandra Faust for her background in PRMs and for taking point on the idea (and doing all the quadrotor work with Lydia Tapia), for Oscar Ramirez and Marek Fiser for their work on our reinforcement learning framework and simulator, for Kenneth Oslund for his heroic last-minute push to collect the indoor robot navigation data, and to our manager James for his guidance, contributions to the paper and support of our navigation work.
 Woohoo! Thanks again everyone!
-the Centaur
Woohoo! Thanks again everyone!
-the Centaur  The biggest "current" in my mind is the person I am currently worried about, my good friend and great Game AI developer Dave Mark. Dave is the founder of the GDC AI Summit ... but was
The biggest "current" in my mind is the person I am currently worried about, my good friend and great Game AI developer Dave Mark. Dave is the founder of the GDC AI Summit ... but was  SO! Hey!
SO! Hey!  As an author, I'm interested in how well my books are doing: not only do I want people reading them, I also want to compare what my publisher and booksellers claim about my books with my actual sales. (Also, I want to know how close to retirement I am.)
In the past, I used to read a bunch of web pages on Amazon (and Barnes and Noble too, before they changed their format) and entered them into an Excel spreadsheet called "Writing Popularity" (but just as easily could have been called "Writing Obscurity", yuk yuk yuk). That was fine when I had one book, but now I have four novels and an anthology out. This could take out half an a hour or more, which I needed for valuable writing time. I needed a better system.
I knew about tools for parsing web pages, like the parsing library Beautiful Soup, but it had been half a decade since I touched that library and I just never had the time to sit down and do it. But, recently, I've realized the value of a great force multiplier for exploratory software development (and I don't mean Stack Exchange): interactive programming notebooks. Pioneered by Mathematica in 1988 and picked up by tools like iPython and its descendent Jupyter, an interactive programming notebook is like a mix of a command line - where you can dynamically enter commands and get answers - and literate programming, where code is written into the documents that document (and produce it). But Mathematica isn't the best tool for either web parsing or for producing code that will one day become a library - it's written in the Wolfram Language, which is optimized for mathematical computations - and Jupyter notebooks require setting up a Jupyter server or otherwise jumping through hoops.
Enter Google's Colaboratory.
Colab is a free service provided by Google that hosts Jupyter notebooks. It's got most of the standard libraries that you might need, it provides its own backends to run the code, and it saves copies of the notebooks to Google Drive, so you don't have to worry about acquiring software or running a server or even saving your data (but do please hit save). Because you can try code out and see the results right away, it's perfect on iterating ideas: no need to re-start a changed program, losing valuable seconds; if something doesn't work, you can tweak the code and try it right away. In this sense Colab has some of the force multiplier effects of a debugger, but it's far more powerful. Heck, in this version of the system you can ask a question on Stack Overflow right from the Help menu. How cool is that?
My prototyping session got a bit long, so rather than try to insert it inline here, I wrote this blog post in Colab! To read more, go take a look at the Colaboratory notebook itself, "A Sip of the Tracking Soup", available at:
As an author, I'm interested in how well my books are doing: not only do I want people reading them, I also want to compare what my publisher and booksellers claim about my books with my actual sales. (Also, I want to know how close to retirement I am.)
In the past, I used to read a bunch of web pages on Amazon (and Barnes and Noble too, before they changed their format) and entered them into an Excel spreadsheet called "Writing Popularity" (but just as easily could have been called "Writing Obscurity", yuk yuk yuk). That was fine when I had one book, but now I have four novels and an anthology out. This could take out half an a hour or more, which I needed for valuable writing time. I needed a better system.
I knew about tools for parsing web pages, like the parsing library Beautiful Soup, but it had been half a decade since I touched that library and I just never had the time to sit down and do it. But, recently, I've realized the value of a great force multiplier for exploratory software development (and I don't mean Stack Exchange): interactive programming notebooks. Pioneered by Mathematica in 1988 and picked up by tools like iPython and its descendent Jupyter, an interactive programming notebook is like a mix of a command line - where you can dynamically enter commands and get answers - and literate programming, where code is written into the documents that document (and produce it). But Mathematica isn't the best tool for either web parsing or for producing code that will one day become a library - it's written in the Wolfram Language, which is optimized for mathematical computations - and Jupyter notebooks require setting up a Jupyter server or otherwise jumping through hoops.
Enter Google's Colaboratory.
Colab is a free service provided by Google that hosts Jupyter notebooks. It's got most of the standard libraries that you might need, it provides its own backends to run the code, and it saves copies of the notebooks to Google Drive, so you don't have to worry about acquiring software or running a server or even saving your data (but do please hit save). Because you can try code out and see the results right away, it's perfect on iterating ideas: no need to re-start a changed program, losing valuable seconds; if something doesn't work, you can tweak the code and try it right away. In this sense Colab has some of the force multiplier effects of a debugger, but it's far more powerful. Heck, in this version of the system you can ask a question on Stack Overflow right from the Help menu. How cool is that?
My prototyping session got a bit long, so rather than try to insert it inline here, I wrote this blog post in Colab! To read more, go take a look at the Colaboratory notebook itself, "A Sip of the Tracking Soup", available at:  When I was a kid (well, a teenager) I'd read puzzle books for pure enjoyment. I'd gotten started with Martin Gardner's mathematical recreation books, but the ones I really liked were Raymond Smullyan's books of logic puzzles. I'd go to Wendy's on my lunch break at Francis Produce, with a little notepad and a book, and chew my way through a few puzzles. I'll admit I often skipped ahead if they got too hard, but I did my best most of the time.
I read more of these as an adult, moving back to the Martin Gardner books. But sometime, about twenty-five years ago (when I was in the thick of grad school) my reading needs completely overwhelmed my reading ability. I'd always carried huge stacks of books home from the library, never finishing all of them, frequently paying late fees, but there was one book in particular - The Emotions by Nico Frijda - which I finished but never followed up on.
Over the intervening years, I did finish books, but read most of them scattershot, picking up what I needed for my creative writing or scientific research. Eventually I started using the tiny little notetabs you see in some books to mark the stuff that I'd written, a "levels of processing" trick to ensure that I was mindfully reading what I wrote.
A few years ago, I admitted that wasn't enough, and consciously began trying to read ahead of what I needed to for work. I chewed through C++ manuals and planning books and was always rewarded a few months later when I'd already read what I needed to to solve my problems. I began focusing on fewer books in depth, finishing more books than I had in years.
Even that wasn't enough, and I began - at last - the re-reading project I'd hoped to do with The Emotions. Recently I did that with Dedekind's Essays on the Theory of Numbers, but now I'm doing it with the Deep Learning. But some of that math is frickin' beyond where I am now, man. Maybe one day I'll get it, but sometimes I've spent weeks tackling a problem I just couldn't get.
Enter puzzles. As it turns out, it's really useful for a scientist to also be a science fiction writer who writes stories about a teenaged mathematical genius! I've had to simulate Cinnamon Frost's staggering intellect for the purpose of writing the Dakota Frost stories, but the further I go, the more I want her to be doing real math. How did I get into math? Puzzles!
So I gave her puzzles. And I decided to return to my old puzzle books, some of the ones I got later but never fully finished, and to give them the deep reading treatment. It's going much slower than I like - I find myself falling victim to the "rule of threes" (you can do a third of what you want to do, often in three times as much time as you expect) - but then I noticed something interesting.
Some of Smullyan's books in particular are thinly disguised math books. In some parts, they're even the same math I have to tackle in my own work. But unlike the other books, these problems are designed to be solved, rather than a reflection of some chunk of reality which may be stubborn; and unlike the other books, these have solutions along with each problem.
So, I've been solving puzzles ... with careful note of how I have been failing to solve puzzles. I've hinted at this before, but understanding how you, personally, usually fail is a powerful technique for debugging your own stuck points. I get sloppy, I drop terms from equations, I misunderstand conditions, I overcomplicate solutions, I grind against problems where I should ask for help, I rabbithole on analytical exploration, and I always underestimate the time it will take for me to make the most basic progress.
Know your weaknesses. Then you can work those weak mental muscles, or work around them to build complementary strengths - the way Richard Feynman would always check over an equation when he was done, looking for those places where he had flipped a sign.
Back to work!
-the Centaur
Pictured: my "stack" at a typical lunch. I'll usually get to one out of three of the things I bring for myself to do. Never can predict which one though.
When I was a kid (well, a teenager) I'd read puzzle books for pure enjoyment. I'd gotten started with Martin Gardner's mathematical recreation books, but the ones I really liked were Raymond Smullyan's books of logic puzzles. I'd go to Wendy's on my lunch break at Francis Produce, with a little notepad and a book, and chew my way through a few puzzles. I'll admit I often skipped ahead if they got too hard, but I did my best most of the time.
I read more of these as an adult, moving back to the Martin Gardner books. But sometime, about twenty-five years ago (when I was in the thick of grad school) my reading needs completely overwhelmed my reading ability. I'd always carried huge stacks of books home from the library, never finishing all of them, frequently paying late fees, but there was one book in particular - The Emotions by Nico Frijda - which I finished but never followed up on.
Over the intervening years, I did finish books, but read most of them scattershot, picking up what I needed for my creative writing or scientific research. Eventually I started using the tiny little notetabs you see in some books to mark the stuff that I'd written, a "levels of processing" trick to ensure that I was mindfully reading what I wrote.
A few years ago, I admitted that wasn't enough, and consciously began trying to read ahead of what I needed to for work. I chewed through C++ manuals and planning books and was always rewarded a few months later when I'd already read what I needed to to solve my problems. I began focusing on fewer books in depth, finishing more books than I had in years.
Even that wasn't enough, and I began - at last - the re-reading project I'd hoped to do with The Emotions. Recently I did that with Dedekind's Essays on the Theory of Numbers, but now I'm doing it with the Deep Learning. But some of that math is frickin' beyond where I am now, man. Maybe one day I'll get it, but sometimes I've spent weeks tackling a problem I just couldn't get.
Enter puzzles. As it turns out, it's really useful for a scientist to also be a science fiction writer who writes stories about a teenaged mathematical genius! I've had to simulate Cinnamon Frost's staggering intellect for the purpose of writing the Dakota Frost stories, but the further I go, the more I want her to be doing real math. How did I get into math? Puzzles!
So I gave her puzzles. And I decided to return to my old puzzle books, some of the ones I got later but never fully finished, and to give them the deep reading treatment. It's going much slower than I like - I find myself falling victim to the "rule of threes" (you can do a third of what you want to do, often in three times as much time as you expect) - but then I noticed something interesting.
Some of Smullyan's books in particular are thinly disguised math books. In some parts, they're even the same math I have to tackle in my own work. But unlike the other books, these problems are designed to be solved, rather than a reflection of some chunk of reality which may be stubborn; and unlike the other books, these have solutions along with each problem.
So, I've been solving puzzles ... with careful note of how I have been failing to solve puzzles. I've hinted at this before, but understanding how you, personally, usually fail is a powerful technique for debugging your own stuck points. I get sloppy, I drop terms from equations, I misunderstand conditions, I overcomplicate solutions, I grind against problems where I should ask for help, I rabbithole on analytical exploration, and I always underestimate the time it will take for me to make the most basic progress.
Know your weaknesses. Then you can work those weak mental muscles, or work around them to build complementary strengths - the way Richard Feynman would always check over an equation when he was done, looking for those places where he had flipped a sign.
Back to work!
-the Centaur
Pictured: my "stack" at a typical lunch. I'll usually get to one out of three of the things I bring for myself to do. Never can predict which one though. 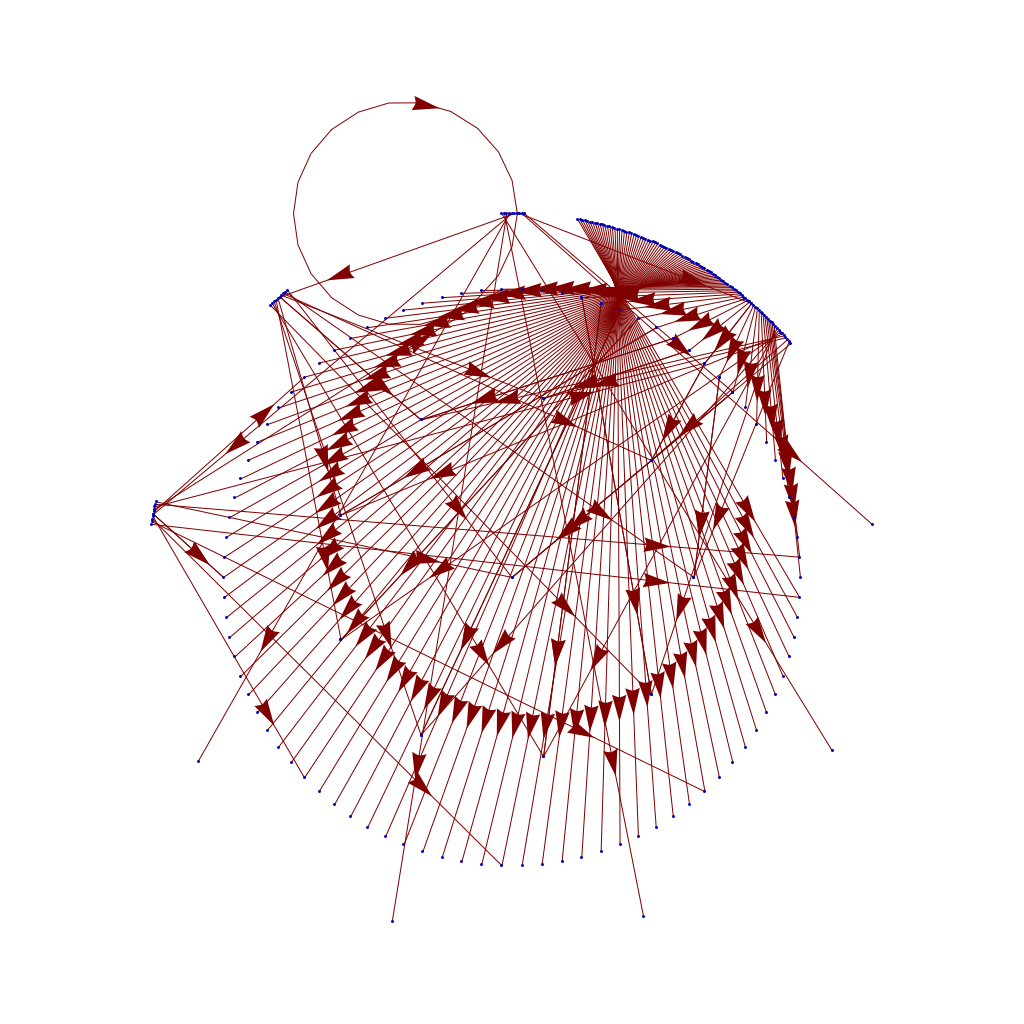 I had way too much data to exploit, so I started to think about culling it out, using the length of the "mumbers" to cut off all the items too big to care about. That led to the key missing insight: my method of mapping mumbers mapped the first digit of each item to the same position - that is, 9, 90, 900, 9000 all had the same angle, just further out. This distance was already a logarithm of the number, but once I dropped my resistance to taking the logarithm twice...
I had way too much data to exploit, so I started to think about culling it out, using the length of the "mumbers" to cut off all the items too big to care about. That led to the key missing insight: my method of mapping mumbers mapped the first digit of each item to the same position - that is, 9, 90, 900, 9000 all had the same angle, just further out. This distance was already a logarithm of the number, but once I dropped my resistance to taking the logarithm twice...
 ... then I could create a transition plot function which worked for almost any mumber in the sets of mumbers I was playing with ...
... then I could create a transition plot function which worked for almost any mumber in the sets of mumbers I was playing with ...
 The actual samples I wanted to play with were larger, like this up to 4 digits:
The actual samples I wanted to play with were larger, like this up to 4 digits:
 This yields a still visible graph:
This yields a still visible graph:
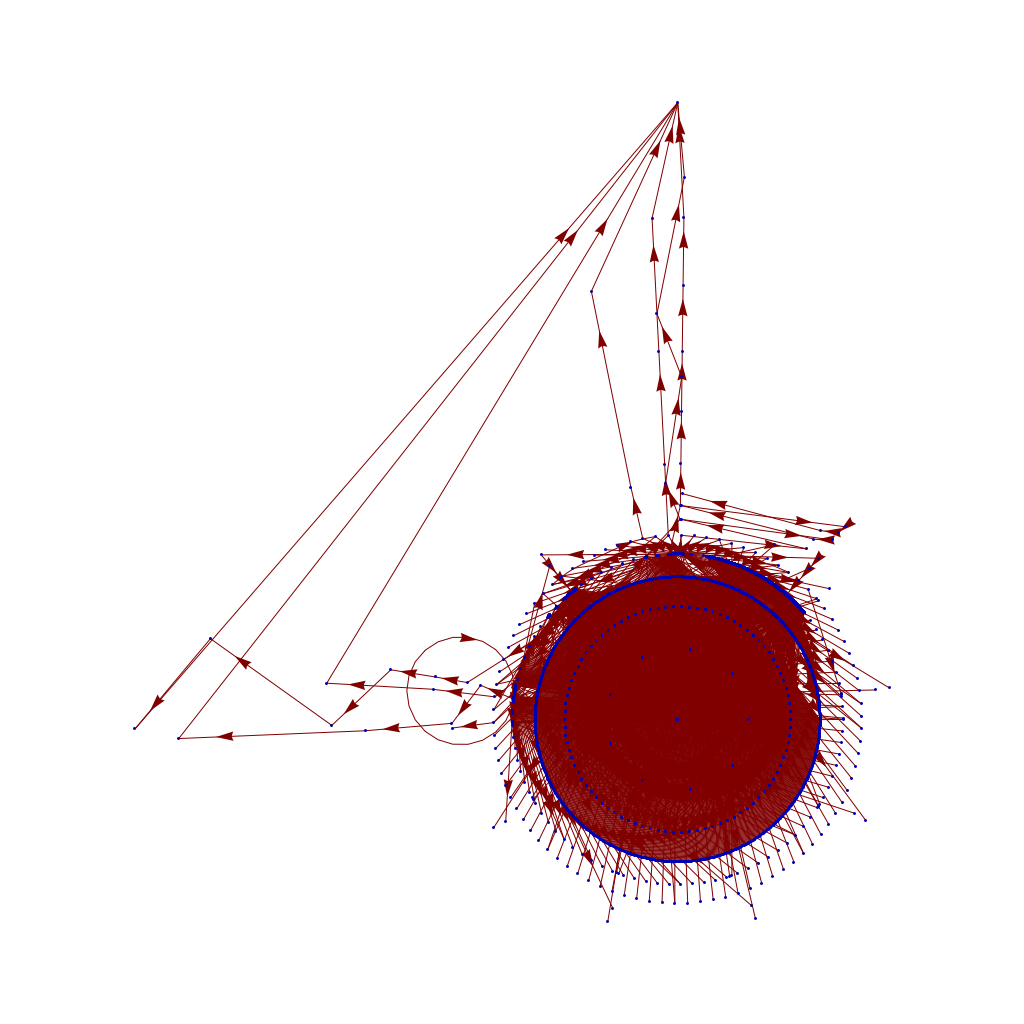 And this, while it doesn't let me visualize the whole space that I wanted, does provide the insight I wanted. The "mumbers" up to 10000 do indeed "produce" most of the space of the smaller "mumbers" (not surprising, as the "mumber" rule 2XYZ produces XYZ, and 52XY produces XYXY ... meaning most numbers in the first 10,000 will be produced by one in that first set). But this shows that sequences of 52 rule transitions on the left produce a few very, very large mumbers - probably because 552552 produces 552552552552 which produces 552552552552552552552552552552552552 which quickly zooms away to the "mumberOverflow" value at the top of my chart.
And now the next lesson: finishing up this insight, which more or less closes out what I wanted to explore here, took 45 minutes. I had 15 allotted to do various computer tasks before leaving Aqui, and I'm already 30 minutes over that ... which suggests again that you be careful going down rabbit holes; unlike leprechaun trails, there isn't likely to be a pot of gold down there, and who knows how far down it can go?
-the Centaur
P.S. I am not suggesting this time spent was not worthwhile; I'm just trying to understand the option cost of various different problem solving strategies so I can become more efficient.
And this, while it doesn't let me visualize the whole space that I wanted, does provide the insight I wanted. The "mumbers" up to 10000 do indeed "produce" most of the space of the smaller "mumbers" (not surprising, as the "mumber" rule 2XYZ produces XYZ, and 52XY produces XYXY ... meaning most numbers in the first 10,000 will be produced by one in that first set). But this shows that sequences of 52 rule transitions on the left produce a few very, very large mumbers - probably because 552552 produces 552552552552 which produces 552552552552552552552552552552552552 which quickly zooms away to the "mumberOverflow" value at the top of my chart.
And now the next lesson: finishing up this insight, which more or less closes out what I wanted to explore here, took 45 minutes. I had 15 allotted to do various computer tasks before leaving Aqui, and I'm already 30 minutes over that ... which suggests again that you be careful going down rabbit holes; unlike leprechaun trails, there isn't likely to be a pot of gold down there, and who knows how far down it can go?
-the Centaur
P.S. I am not suggesting this time spent was not worthwhile; I'm just trying to understand the option cost of various different problem solving strategies so I can become more efficient. 
 SO! There I was, trying to solve the mysteries of the universe, learn about deep learning, and teach myself enough puzzle logic to create credible puzzles for the Cinnamon Frost books, and I find myself debugging the fine details of a visualization system I've developed in Mathematica to analyze the distribution of problems in an odd middle chapter of Raymond Smullyan's
SO! There I was, trying to solve the mysteries of the universe, learn about deep learning, and teach myself enough puzzle logic to create credible puzzles for the Cinnamon Frost books, and I find myself debugging the fine details of a visualization system I've developed in Mathematica to analyze the distribution of problems in an odd middle chapter of Raymond Smullyan's  I meant well! Really I did. I was going to write a post about how finding a solution is just a little bit harder than you normally think, and how insight sometimes comes after letting things sit.
I meant well! Really I did. I was going to write a post about how finding a solution is just a little bit harder than you normally think, and how insight sometimes comes after letting things sit.
 But the tools I was creating didn't do what I wanted, so I went deeper and deeper down the rabbit hole trying to visualize them.
But the tools I was creating didn't do what I wanted, so I went deeper and deeper down the rabbit hole trying to visualize them.
 The short answer seems to be that there's no "there" there and that further pursuit of this sub-problem will take me further and further away from the real problem: writing great puzzles!
The short answer seems to be that there's no "there" there and that further pursuit of this sub-problem will take me further and further away from the real problem: writing great puzzles!
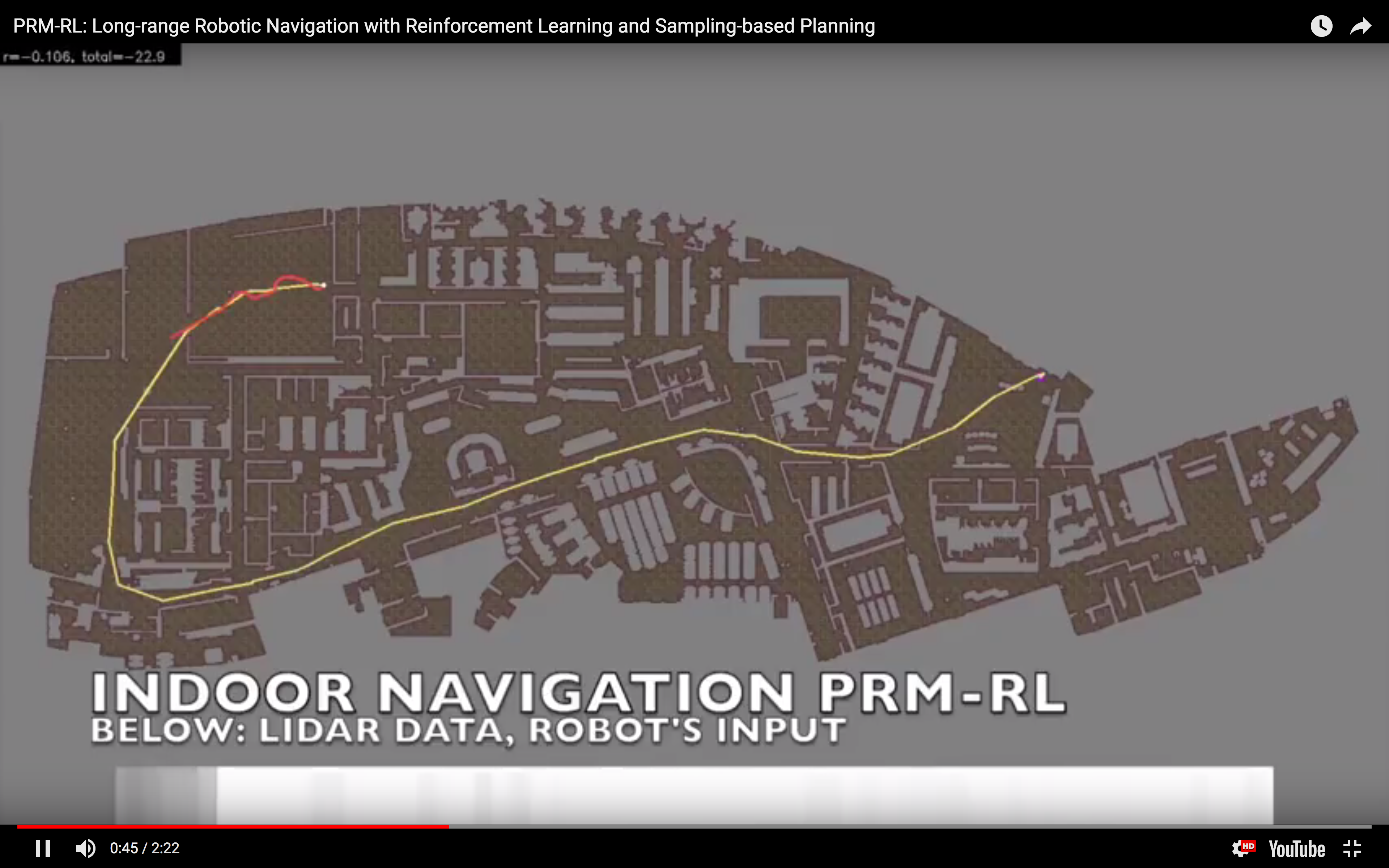 I often say "I teach robots to learn," but what does that mean, exactly? Well, now that one of the projects that I've worked on has been announced - and I mean, not just on
I often say "I teach robots to learn," but what does that mean, exactly? Well, now that one of the projects that I've worked on has been announced - and I mean, not just on 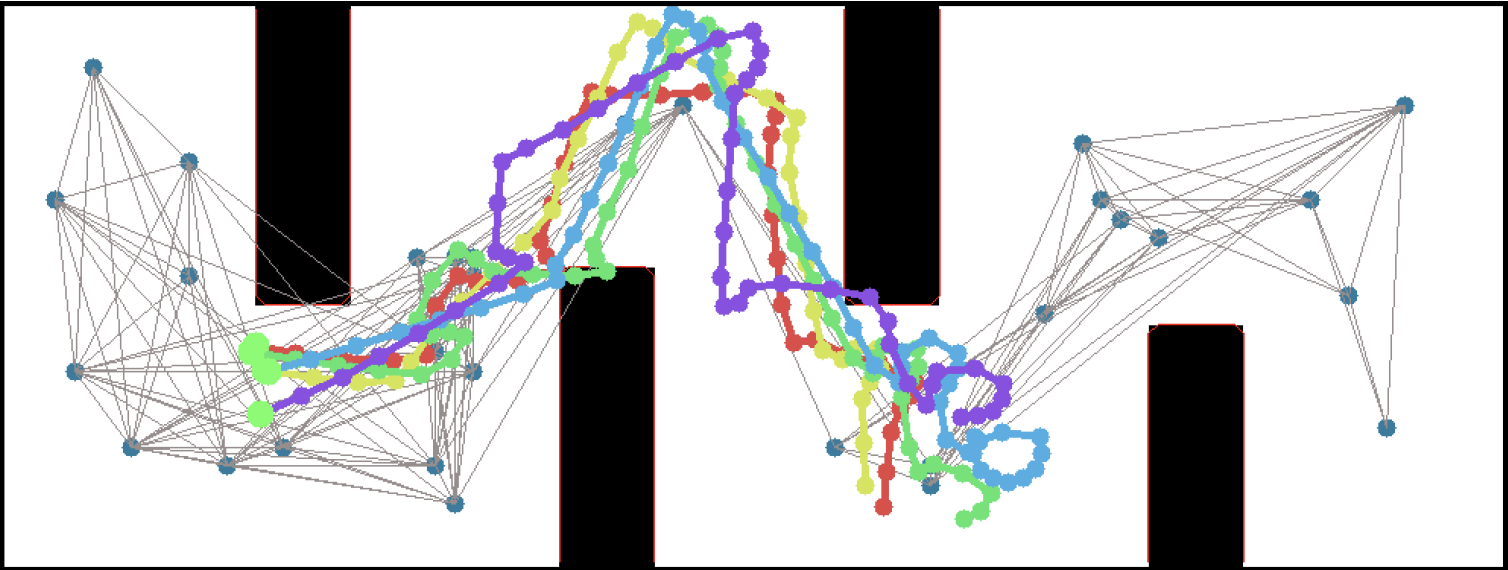 This work includes both our group working on office robot navigation - including Alexandra Faust, Oscar Ramirez, Marek Fiser, Kenneth Oslund, me, and James Davidson - and Alexandra's collaborator Lydia Tapia, with whom she worked on the aerial navigation also reported in the paper. Until the ICRA version comes out, you can find the preliminary version on arXiv:
This work includes both our group working on office robot navigation - including Alexandra Faust, Oscar Ramirez, Marek Fiser, Kenneth Oslund, me, and James Davidson - and Alexandra's collaborator Lydia Tapia, with whom she worked on the aerial navigation also reported in the paper. Until the ICRA version comes out, you can find the preliminary version on arXiv:


 So at Dragon Con I had a reading this year. Yeah, looks like this is the last year I get to bring all my books - too many, to heavy! I read the two flash fiction pieces in
So at Dragon Con I had a reading this year. Yeah, looks like this is the last year I get to bring all my books - too many, to heavy! I read the two flash fiction pieces in 








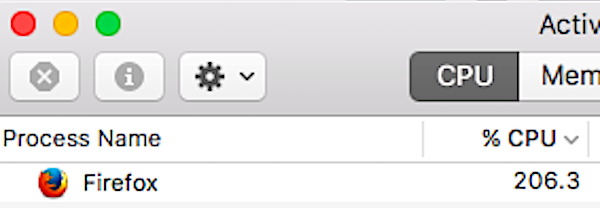
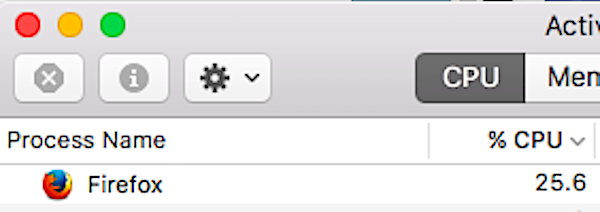
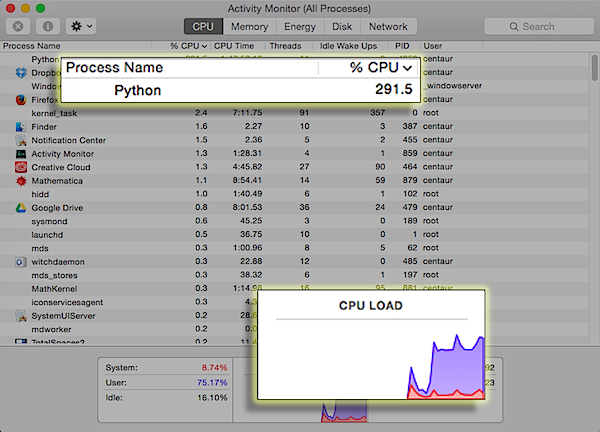
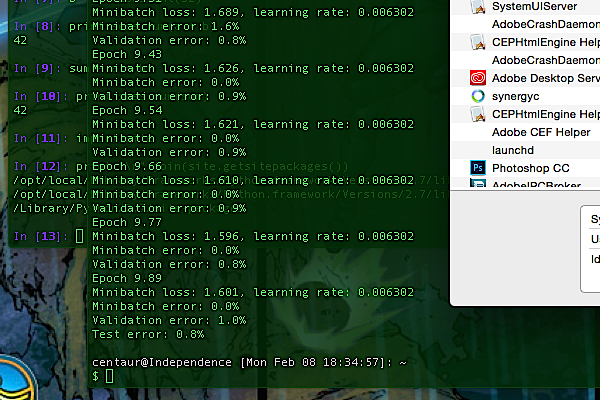 Well. 99.2% correct, it seems. Not bad for a
Well. 99.2% correct, it seems. Not bad for a