Back from the Embodied AI Workshop! And TIL (today I learned, though not the today of the blogging every day post) that "home again, home again, jiggity jig" isn't originally just a throw-away line from J.F. Sebastian's autonomous creations in Blade Runner, but actually is a centuries-old nursery rhyme called "To Market, To Market": https://poets.org/poem/market-market
To market, To market, To buy a fat pig. Home again, Home again, Jiggity jig.
I may be a carnivore, but I find the treatment of animals in a lot of older literature ... disturbing. Regardless, I'm home again, and since another year has passed, that means there's a different car from the Clemson autonomous driving team on display in the Greenville-Spartanburg Airport:
On the theme of dubious autonomous creatures, I've said it before, but now I'll say it here: an autonomous vehicle without a physical steering wheel is a bug, just waiting to turn your car into a one-ton paperweight when the software inevitably bricks. Send an engineer out with a gamepad controller all you want: sooner or later you'll need a tow in an awkward situation (say, for example, an underground parking garage in Palo Alto which is too windy for a tow truck to get into ... yes, I do have personal experience with this, why do you ask?) requiring your new paperweight to be serviced in place.
Pull up your pants, turn your ballcap forward, and install a steering wheel.
-the Centaur
Pictured: A fountain in the Greenville-Spartanburg Airport, and the aforementioned self-driving car. I don't think it had a steering wheel, front or back, but perhaps that was just the angle I could see in.
Programmers scramble about, trying to meet a deadline. CODEFINGER watches as an industrial coding AGENT creeps closer and closer to BOND's vital job functions.
BOND (nervously): Do you expect me to prompt?
CODEFINGER (laughing): No, Mister Bond! I expect your job to die!
The industrial coding AGENT cuts CODEFINGER in half with an industrial grade laser.
BOND (shocked): You killed him!
AGENT: You're right! Let me fix that ...
BOND (untying himself): I'll just show myself out ...
"I know, KITT, but let's try to take out his right front tire."
Technically it is possible to swing a stick at CVPR and not hit a self-driving vehicle, but our best VLA robotics foundation models only achieve 38% at this task, and even humans struggle to do it well.
-the Centaur
Pictured: Two companies inadvertently creating a classic scene out of Knight Rider, where KITT goes up against Goliath, a truck armored with the same invulnerable material out that KITT is:
I don't know. I enjoyed the scene as a kid, but I have a hard time thinking that Goliath would have done well in a collision against a barricade of a dozen or so cement mixer trucks, much less an actual tank, which typically weighs two to three times as much as a fully laden truck. Newton's a bitch!
You survived the Embodied AI Workshop and all you got was that lousy t-shirt!
I'm promising myself not to over-complicate this post, so here's the short story: it went well! But we were making changes up to the previous day, so between the time that we printed the above poster and the actual talk, two of the speakers had changed - one speaker replaced their own backup, and another speaker who had dropped out was replaced by a volunteer speaker the afternoon before!
As CVPR (our parent conference) said, "Printed materials may be out of date ... check the website!" Which we did keep up to date: https://embodied-ai.org/cvpr2026 ... overall, though, the workshop was well attended. The best attended talk was my buddy Lewis Chiang's, a roboticist at Google DeepMind who I always thought was a superstar and I guess he's well on his way:
Over 70 people attended the talk and at least a dozen people were remote. While there were a few open seats up front, it still created a standing-room-only vibe:
All in all we had nine speakers, two highlight sessions for embodied AI challenges and accepted papers, a poster session, and a concluding debate. The very first picture is me, Lewis and Dinesh, another speaker at the workshop, discussing the nuances and challenges of safety in long-horizon embodied AI - a fancy way of asking "how to keep our agents from killing us if we let them loose."
There's more to say about this - CVPR is huge, so huge that it perhaps it was a mistake to go see the Backrooms movie after wandering around the massive Colorado Convention Center:
But, the long and the short of it is, we survived!
And now it's time to enjoy the rest of the conference ... at a much slower pace.
-the Centaur
Pictured: the final debate, the image of the schedule poster, the schedule poster in action, Lewis's talk, the standing room only audience, the keynote rooms, the expo floor and CVPR's massive collection of posters, the EAI7 dinner, and me in front of the expo proper. Now it's time for a nap.
The Embodied AI Workshop starts in just under an hour at Room 107 at the Colorado Convention Center! Hope to see you all there, or you'll all be square.
Well.
All of you wouldn't fit in the room, so I guess you don't have to be square if you're not there. But you can find out more about it here: https://embodied-ai.org/cvpr2026/
SO! I am pleased to announce that the Embodied AI Workshop returns in its seventh year at the CVPR conference! No playing of spoons for the Sylvester McCoy fans - this seventh incarnation will focus on World Models for Embodied AI - which is a fancy way of saying we're trying to take all that generative AI goodness that you see in language models and image / video models and turn it towards agents controlling bodies.
Once again, I have thrown my body on the grenade of a banner image, and, as usual, since "the client" is an artificial intelligence workshop, I have unabashedly chosen to use generative AI to help generate it. Frankly, it seems to be improving: I asked on riffs on the previous year's characters (see below) and the Denver skyline and, more or less, it was able to recreate characters that looked like I asked for. I think ChatGPT managed a good job of taking our mascot robot guitarist and making her into a climber ... down to the headphones, which is a nice detail!
For the record, these were produced with Midjourney and ChatGPT for ideation, ChatGPT for character creation and tweaking, Midjourney for image extension and modifying ... and my expertise, as a physical artist and 30+ year digital image jockey, using my skills to manipulate a 200+ layer Photoshop file.
If you think you can create any of my graphics using an off-the-shelf generative AI system ... good luck.
[Why, yes, I have a number of friends who absolutely hate generative AI ... why do you ask?]
This year's theme of World Models for Embodied AI is played out in three subthemes: World Models for Action and Evaluation (using world models of physics, or video models where physics is implicit), the Resurgence of Classic Methods (embodied AI using "older" techniques such as reinforcement learning and its kissing cousin, model-predictive control), and Long-Horizon Embodied Intelligence (embodied AI for complicated tasks with many steps, particularly where safety is involved).
You can read more about it at https://embodied-ai.org/cvpr2026/ or at the announcement on the Embodied Artificial Intelligence Medium blog. We'll keep the site up-to-date, but will publish major announcements (like speaker confirmations, challenge confirmations, and what day of the week will we actually hold the workshop, when they tell us that is) on the Medium blog.
-the Centaur
Pictured: this year and last year's banner images, formatted for social media sharing on Mastodon.
Okay, today's post was going to be a post about friends and family and the value of organizing dinners.
Instead, I'd like to blog that it's late, and I'm tired.
Our five cats have not been getting along of late, and so we've separated the newest addition from the O.G.'s (the Original Girls, who actually aren't the original gangsters at all, but are the new(ish) kittens picking on the new(est) kitten). So, I was up super late socializing them yesterday, and am real damn tired today.
So please enjoy this picture of late-night pound cake and milk. Goodnight.
-the Centaur
Pictured: Pound cake, vanilla almond milk, and Pattern Recognition and Machine Learning, a fantastic, highly mathematical tour of machine, deep and Bayesian learning, my latest evening read.
I'm working on a paper on "The Cognitive Science of Scenes and Sequels" with my friend Kenny Moorman. We're attempting to harmonize "scenes and sequels" from professional writing craft with the findings of the cognitive science of story understanding ... and I'm presenting it at WorldCon in a little over a week.
It's been slow going due to the amount of research involved---at least seven narrative disciplines affect our work, and relevant papers and projects go back fifty years---not to mention my periodic struggles with writer's block whenever I switch projects (as two other writing deadlines are overlapping this one).
SO! I've been working on the paper a lot of late, scribbling on printouts over coffee, then editing over dinner, staying up late at night to harmonize details. And I was plugging away at the "WC:AD" (WorldCon ACademic) paper when I hit a new section my collaborator had added on "the Lorentzian Argument."
Huh, I thought, I've been working on general relativity, where Lorentzian metrics show up; I wonder if this is the same Lorentz? Surely, I thought, I could take a stab at the section. Then I saw Kenny had moved the section on "Implications for the Transgender Narrative" to just after "The Lorentzian Argument."
He'd done so on purpose. There were notes there. There was a deep connection between them.
I realized there was no way I could fill out this section; I had to move on.
Then I woke up.
-Anthony
Pictured: Working on WC:AD at Monterey by the Mall. I wonder if the strength of the margarita has any effect on the bizarreness of the dreams?
P.S. In case it wasn't clear, our paper doesn't have implications for the transgender narrative, nor is there a Lorentzian argument in narrative theory---at least, that I am aware of. My brain made it all up probably because I'm also studying general relativity and transgender issues in the background for other projects.
The final session of the Advances in Social Robot Navigation Workshop at ICRA 2025 is happening NOW. It's been a great conference so far, with lots of great talks and debate ...
Even though there's no-one in the row in front of me, we've had 50-60 people in person or online all day:
More on the workshop later ... back to taking notes now!
Lots of great social navigation work this conference ... we are really seeing some advances. Even in the proliferation of form factors, some of which you can see above, such as the base with humanoid, looks like it will help social robotics. More and cheaper robots - and more varied form factors - should make it easier to find the right robot for the job.
Onward! Three or four more sessions of talks, and then it's the workshop ...
-the Centaur
Pictured: The room our workshop will be held in, and two robots "shaking hands".
Due to a snafu with the way the date and time were programmed into OpenReview, and having NOTHING AT ALL to do with us getting slightly fewer papers than we wanted (well, actually ....) we have extended the deadline for the Embodied AI Workshop's Call for Papers to Friday, May 23rd, AOE (Anywhere on Earth):
Please submit your 2-page extended abstracts on embodied AI, especially related to this year's themes of Embodied AI Solutions, Advances in Simulation, Generative Methods for Embodied AI, and Foundation Models for Embodied AI!
SO! I'm at ICRA, the big robotics conference (okay, okay, ONE of the big robotics conferences, the others being IROS and RSS) and I would be remiss if I didn't point out that our workshop, "Advances in Social Robot Navigation: Planning, HRI and Beyond" will be held this Friday, May 23rd!
Building on our successful series of workshops at ICRA'22, IROS'23, and RSS'24, as well as the Social Navigation Symposium, the AISRN workshop aims to investigate key aspects that make robot navigation more acceptable, legible, and social. It's been a great year for social navigation at ICRA; come join us!
Hey folks, I have been neck deep in preparations for a couple of workshops - the Advances in Social Robot Navigation one I already mentioned, coming up next week, but also the Embodied AI Workshop #6!
The Embodied AI workshop brings together researchers from computer vision, language, graphics, and robotics to share and discuss the latest advances in embodied intelligent agents. EAI 2025’s overaching theme is Real-World Applications: creating embodied AI solutions that are deployed in real-world environments, ideally in the service of real-world tasks. Embodied AI agents are maturing, and the community should promote work that transfers this research out of simulation and laboratory environments into real-world settings.
So, yes, it's late and i'm tired, but i couldn't just leave it at that, because the above quote is so good. I ran across this from George Bernard Shaw in a book on mentoring (which I can't access now, due to cat wrangling) and snapped that picture to send to my wife. In case it's hard to read, the quote goes:
The single biggest problem with communication is the illusion that it has taken place.
This was a great quote to send to my wife because our first vow is communication, yet we have observed problems with communication a lot. Often, when the two of us think we are on the same page, frequently we have each communicated to each other something different using similar-sounding language.
I was struck by how hard it is to get this right, even conceptually, when I was skimming The Geometry of Meaning, a book I recently acquired at a used bookstore, which talks about something called something like a "semantic transfer function" (again, I can't look up the precise wording right now as I am cat wrangling). But the basic idea presented is that you can define a function describing how the meaning that is said by one person is transformed into the meaning that is heard by another.
If you pay attention to how communication fails, it becomes clear how idealized - how ultimately wrongheaded - it is. Because you may have some idea in your head, but you had some reason to communicate it as a speech act, and something you wanted to accomplish inside the hearer's head - but there's no guaranteed that what you said is what you meant, and much less whether what was heard was what was said, or whether the interpretation matched what was heard, much less said or meant.
But even if they took your meaning - even if the semantic transfer function worked perfectly to deliver a message, there is no guarantee that that the information that is delivered will cause the appropriate cognitive move in the hearer's brain. Perhaps we're all familiar with the frustration of trying to communicate an inconveniently true fact to someone who stubbornly won't absorb it because it's politically inconvenient for them, but the matter is worse if your speech was designed to prompt some action - as Loki and one of the kittens just found out, when he tried to communicate "stop messing with me, you're half my size, you little putz" as a speech act to get the kitten to leave him alone. It had the opposite effect, and the kitten knocked itself onto the floor when it tried to engage a sixteen-pound ball of fur and muscle.
So what does that have to do with drainage?
My wife and I have had a number of miscommunications about the cats recently, ones where we realized that we were using the same words to talk about different things, and didn't end up doing things the way each other wanted. But it isn't just us. The cats stayed indoors mostly today, because workmen came by to work on a drainage project. I went out to sync up with the foreman about adding a bit to the next phase of work, and he offhandedly said, "sure, now that we're finished with the front."
"But wait," I said. "What about the drains in the front?"
"What drains in the front?" he asked.
We stared at each other blankly for a moment, then walked around the house. It rapidly became clear that even though we had used the same words to talk about the same job related to the same problem - excess water tearing through the mulch - we had meant two completely different things by it: I had meant fixing the clogged drains of the downspout of the gutter that were the source of the water, and he had took that to mean fixing the clogged drains where that water flowed out into the rest of the yard. A rainstorm soon started, and we were able to both look at the problem directly and agree what needed to be fixed. (The below picture was from later in the night, from another drain that was clogged and in need of repair).
It turns out the things that I wanted fixed - the things that had prompted me to get the job done in the first place - were so trivial that he threw them into the job at no extra cost. And the things that the foreman had focused on fixing, which also needed to be fixed but didn't seem that important from the outside, were actually huge jobs indicative of a major mis-step on the original installation of the drainage system.
We resolved it, but it took us repeatedly syncing up, listening for issues as we spoke, and checking back with each other - in both directions - when things didn't sound quite right for us to first notice and then resolve the problem. Which is why I found it so apropos to come across that Shaw quote (which I can look up now that the cats have settled down, it's in The Coaching Habit) as it illustrated everything me and my wife had been noticing about this very problem.
Just because you've said the words doesn't mean they were heard. And just because they're said back to you correctly doesn't mean that the hearer actually heard you. If you spoke to prompt action, then it's important to check back in with the actor and make sure that they're doing what you wanted them to - and even if they're not, it's important to figure out whether the difference is their problem - or is on your end, because you haven't actually understood what was involved in what you asked them to do.
So, yeah. The biggest problem with communication is the illusion that it has taken place - so rather than trust the illusion in your mind, take some time to verify the facts on the ground.
-the Centaur
Pictured: "Shaw!", obstreperous cats, and a malfunctioning drain.
There's an ongoing debate over whether human emotions are universal: I, like many researchers, think that there was solid work done by Ekman back in the day that demonstrated this pretty conclusively with tribes with little Western contact, but some people seem determined to try to pretend that evidence can be made not to exist once it's been collected, if you just argue loudly enough about how you think it's wrong.
(The evidence is wrong?)
Yet my cat can look surprised, or scared, or angry, or alarmed, or content, or curious. It's fairly well established that some emotions, like the self-conscious ones of shame or pride, have highly variable, culturally-determined expressions (if they have consistent expressions at all). But when animals very different from us can still communicate emotions, it's hard to believe none of it is universal.
(The evidence is wrong? What's wrong with you people?)
-the Centaur
P.S. If you subscribe to the anthropic fallacy fallacy, please do not bother to tell me that I'm falling into the anthropic fallacy, because you're the one trapped in a fallacy - sometimes surprise is just surprise, just like a heart is still a heart when that heart is found an animal, and not a "deceptively heart-like blood pump."
Pictured: Loki, saying, "What, you expect me to do something? I'm a cat. I was busy, sleeping!"
Please send us what you've got! Just between you and me and the fencepost, if we get about 7+/-2 more submissions, we'll have enough to call it done for the year and won't need to extend the CFP, so we can get on with reviewing the papers and preparing for the workshop. So please submit!
-the Centaur
Pictured: the very nice logo for the Embodied AI Workshop, a joint effort of me, my co-organizer Claudia, and I think one of Midjourney or DALL-E. Yes, there's generative AI in there, but it took a good bit of prompting to get the core art, and lot of work in Photoshop after that to make it usable.
So! While working on The Neurodiversiverse I've been reading up a lot on neurodiversity. According to Devon Price's Unmasking Autism, autism is massively undiagnosed, and for good---well, understandable---reasons. From parents concerned about their uncommunicative children or fans of cold geniuses on Sherlock and the Big Bang Theory, our culture focuses a lot on certain stereotypes of autism---while ignoring a much larger group of people who suffer from the same underlying conditions in their brains, but who are able to "mask" their behavior to appear much more "high functioning" or even "neurotypical".
As you might imagine, spending your whole day trying to react in ways that are fundamentally unnatural to you---and trying to hide the ways that you react that are natural to you---can stress people the fuck out. But many people never get a diagnosis---either because they're from a disadvantaged group, or because they don't want to risk the stigma and potential negative consequences of a diagnosis, or because they mask too well and no-on notices how they are suffering. But if you don't understand your condition, you may employ coping strategies which may actually do more long-term harm than good.
Well, now there are a lot of online tests and self-help books and even sympathetic therapists who can help people understand themselves better. While I've always known I was a bit strange---mostly solitary, typically withdrawn at family gatherings when I was a child, or explicitly labeled as having a weird brain---I've never pursued a diagnosis of any kind---in the past, because I didn't feel I had any trouble coping to the point that I needed help, and in the present, because having a disability label attached to you can have negative social and legal consequences that I have no interest in dealing with.
BUT! The personal stories of Unmasking Autism resonated a lot with me, and I now have friends who have gone through formal adult diagnoses of autism and ADHD, as well as an undiagnosed autistic friend who clearly is autistic and has to manage her life the way a masking autistic person does, but who did not pursue a diagnosis for precisely the same reasons that many other masking autistics do not pursue it: unless your condition is very severe, it isn't clear that a formal diagnosis can actually get you help, and it can often get you a lot of hurt. But UNDERSTANDING it, that, that we can now do.
So! And I note I again use "So!" at the start of a paragraph. Is that a verbal tic? Who cares? SO ANYWAY ...
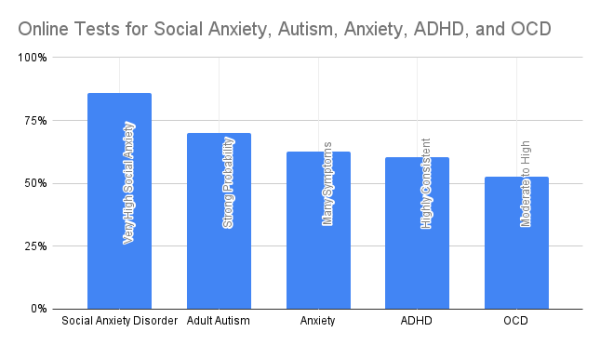
Diagnoses of autism, and other neurodivergences! The neurodivergence I identify most with is Social Anxiety Disorder---in fact, this is the neurodivergence I chose for the protagonist of "Shadows of Titanium Rain", my own submission to The Neuroversiverse. But other people have suggested I have characteristics of OCD, or ADHD, or Autism, and I even went into therapy for stress and anxiety during the pandemic. So I decided to take five online tests: Social Anxiety Disorder, Autism, Anxiety, ADHD, and OCD.
The results are at the top of the blog---and I already gave away the game through the order I listed them. Normalizing all the scores from zero to a hundred, most of the tests put the boundary of "you've got the thing" at somewhere around 60-70% of the possible points you could score - let's call it at 2/3, or 66%, shall we? OCD scored the lowest - roughly 53%, which the test judged as "you've got OCD tendencies, but not OCD." ADHD was a little higher, 60%, and general Anxiety still higher, 63%. But none of these were over the "you've got it" thresholds for these tests---they just indicated a general tendency in that direction.
Things start to change with Autism: my test results for "Adult Autism" (*cough* MISNOMER) were 70%, well within the boundary of "you've very probably got it". Some of my friends are quite surprised to hear this, as they didn't see this in me at all; I guess my condition is "mild" and/or I mask very well.
But Social Anxiety Disorder? 86%, off the charts. And this wasn't a surprise: not only do I have a huge raft of coping mechanisms to help me deal with social situations, I also have some of the more subtle symptoms of Social Anxiety Disorder that you might not expect would be symptoms. For example, in certain socially awkward situations, I can partially stumble while walking. Most people, even those close to me, never notice that my foot briefly drags when we're walking and something socially awkward occurs - yet balance and coordination issues are a symptom of social anxiety.
Again, I've not pursued a formal diagnosis, and I don't plan to. But understanding these things about myself helps me understand why I've built a mass of coping mechanisms and masking strategies in my life---and can help me start to construct a healthier way to cope with the world within which I live.
If you feel alienated by your world, perhaps that's something you could try too.
Still at the Conference on Robot Learning. LOTS of robot dogs were about, lots of diffusion model and transformer work, and lots of language model planning. More later, gotta crash.
So, I'm proud to announce my next venture: Logical Robotics, a robot intelligence firm focused on making learning robots work better for people. My research agenda is to combine the latest advances of deep learning with the rich history of classical artificial intelligence, using human-robot interaction research and my years of experience working on products and benchmarking to help robots make a positive impact.
Recent advances in large language model planning, combined with deep learning of robotic skills, have enabled almost magical developments in explainable artificial intelligence, where it is now possible to ask robots to do things in plain language and for the robots to write their own programs to accomplish those goals, building on deep learned skills but reporting results back in plain language. But applying these technologies to real problems will require a deep understanding of both robot performance benchmarks to refine those skills and human psychological studies to evaluate how these systems benefit human users, particularly in the areas of social robotics where robots work in crowds of people.
Logical Robotics will begin accepting new clients in May, after my obligations to my previous employer have come to a close (and I have taken a break after 17 years of work at the Search Engine That Starts With a G). In the meantime, I am available to answer general questions about what we'll be doing; if you're interested, please feel free to drop me a line at via centaur at logicalrobotics.com or take a look at our website.