I often say "I teach robots to learn," but what does that mean, exactly? Well, now that one of the projects that I've worked on has been announced - and I mean, not just on
arXiv,
the public access scientific repository where all the hottest reinforcement learning papers are shared, but actually, accepted into the
ICRA 2018 conference - I can tell you all about it!
When I'm not roaming the corridors hammering infrastructure bugs, I'm trying to teach robots to roam those corridors - a problem we call
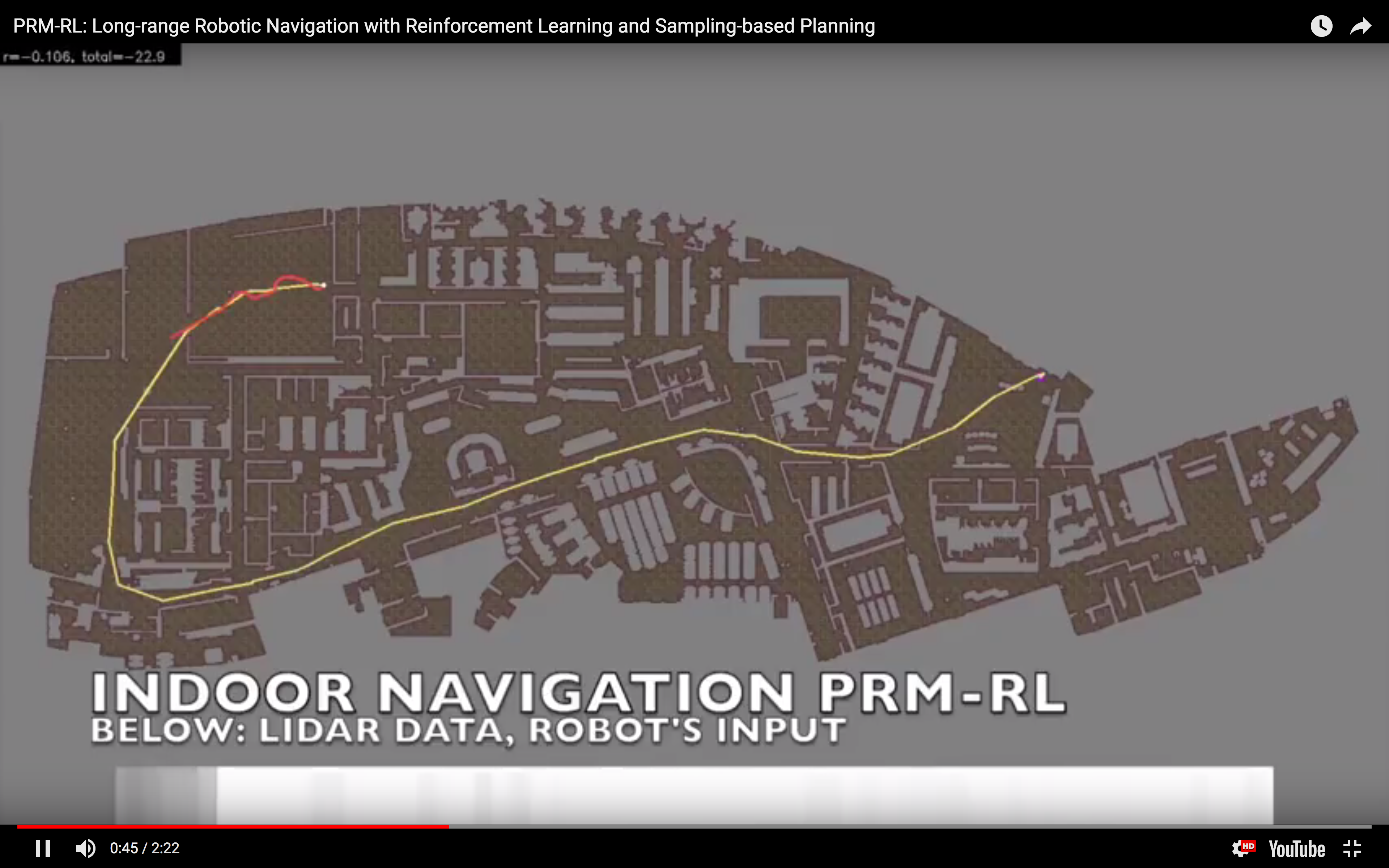
robot navigation. Our team's latest idea combines "traditional planning," where the robot tries to navigate based on an explicit model of its surroundings, with "reinforcement learning," where the robot learns from feedback on its performance.
For those not in the know, "traditional" robotic planners use structures like graphs to plan routes, much in the same way that a GPS uses a roadmap. One of the more popular methods for long-range planning are
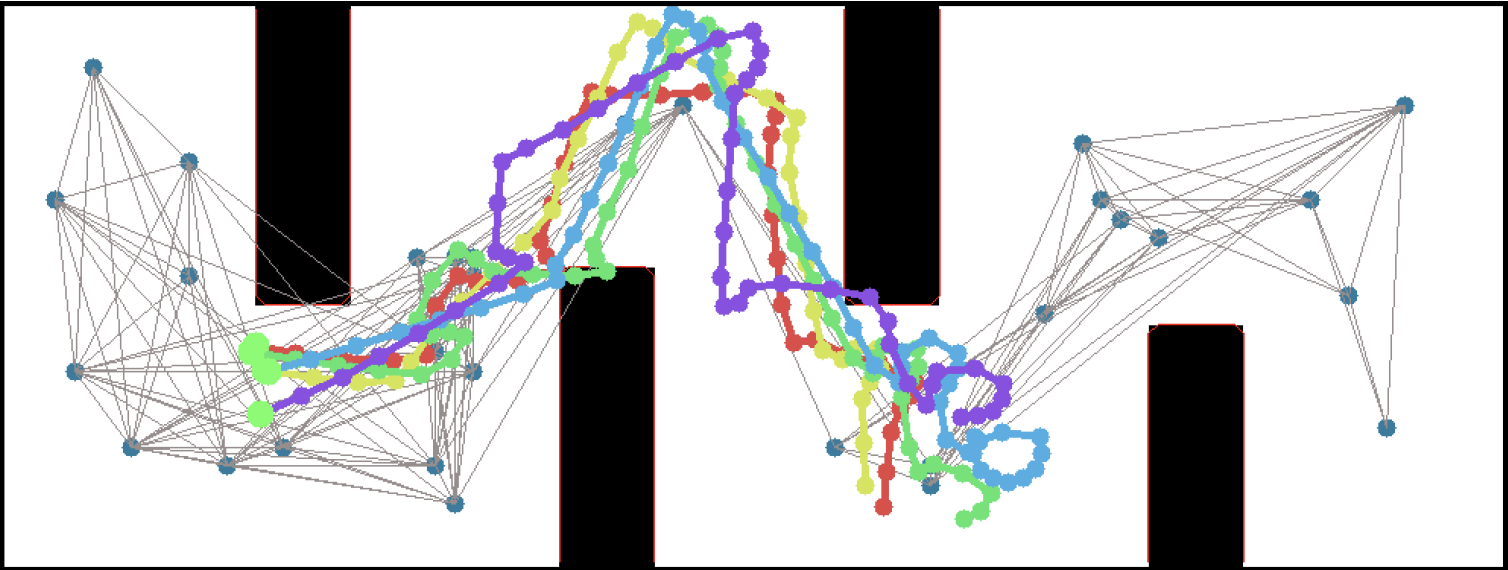
probabilistic roadmaps, which build a long-range graph by picking random points and attempting to connect them by a simpler "local planner" that knows how to navigate shorter distances. It's a little like how you learn to drive in your neighborhood - starting from landmarks you know, you navigate to nearby points, gradually building up a map in your head of what connects to what.
But for that to work, you have to know how to drive, and that's where the local planner comes in. Building a local planner is simple in theory - you can write one for a toy world in a few dozen lines of code - but difficult in practice, and making one that works on a real robot is quite the challenge. These software systems are called "
navigation stacks" and can contain dozens of components - and in my experience they're hard to get working and even when you do, they're often brittle, requiring many engineer-months to transfer to new domains or even just to new buildings.
People are much more flexible, learning from their mistakes, and the science of making robots learn from their mistakes is
reinforcement learning, in which an agent learns a policy for choosing actions by simply trying them, favoring actions that lead to success and suppressing ones that lead to failure. Our team built a deep reinforcement learning approach to local planning, using a state-of-the art algorithm called DDPG (
Deep Deterministic Policy Gradients)
pioneered by DeepMind to learn a navigation system that could successfully travel several meters in office-like environments.
But there's a further wrinkle: the so-called "
reality gap". By necessity, the local planner used by a probablistic roadmap is simulated - attempting to connect points on a map. That simulated local planner isn't identical to the real-world navigation stack running on the robot, so sometimes the robot thinks it can go somewhere on a map which it can't navigate safely in the real world. This can have disastrous consequences - causing robots to tumble down stairs, or, worse, when people follow their GPSes too closely without looking where they're going, causing
cars to tumble off the end of a bridge.
Our approach, PRM-RL, directly combats the reality gap by combining probabilistic roadmaps with deep reinforcement learning. By necessity, reinforcement learning navigation systems are trained in simulation and tested in the real world. PRM-RL uses a deep reinforcement learning system as
both the probabilistic roadmap's local planner
and the robot's navigation system. Because links are added to the roadmap only if the reinforcement learning local controller can traverse them, the agent has a better chance of attempting to execute its plans in the real world.
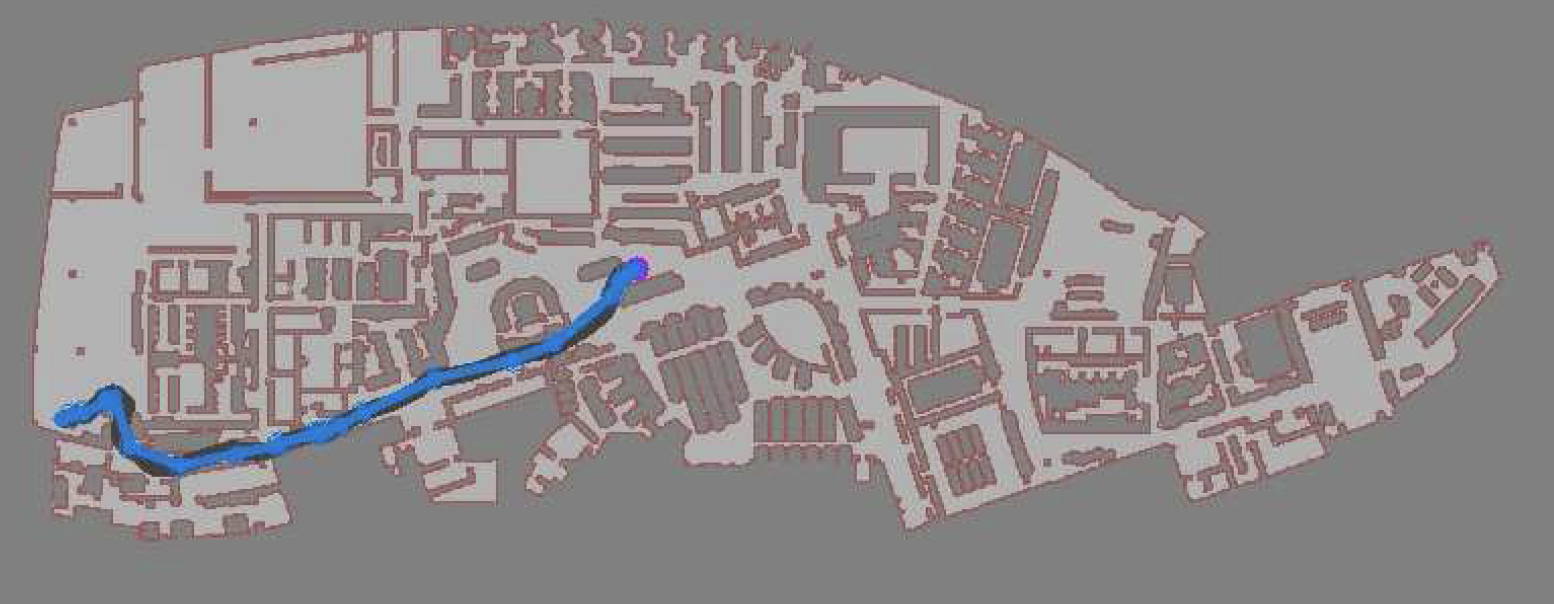
In simulation, our agent could traverse hundreds of meters using the PRM-RL approach, doing much better than a "straight-line" local planner which was our default alternative. While I didn't happen to have in my back pocket a hundred-meter-wide building instrumented with a mocap rig for our experiments, we were able to test a real robot on a smaller rig and showed that it worked well (no pictures, but you can see the map and the actual trajectories below; while the robot's behavior wasn't as good as we hoped, we debugged that to a networking issue that was adding a delay to commands sent to the robot, and not in our code itself; we'll fix this in a subsequent round).
This work includes both our group working on office robot navigation - including Alexandra Faust, Oscar Ramirez, Marek Fiser, Kenneth Oslund, me, and James Davidson - and Alexandra's collaborator Lydia Tapia, with whom she worked on the aerial navigation also reported in the paper. Until the ICRA version comes out, you can find the preliminary version on arXiv:
https://arxiv.org/abs/1710.03937
PRM-RL: Long-range Robotic Navigation Tasks by Combining Reinforcement Learning and Sampling-based Planning
We present PRM-RL, a hierarchical method for long-range navigation task completion that combines sampling-based path planning with reinforcement learning (RL) agents. The RL agents learn short-range, point-to-point navigation policies that capture robot dynamics and task constraints without knowledge of the large-scale topology, while the sampling-based planners provide an approximate map of the space of possible configurations of the robot from which collision-free trajectories feasible for the RL agents can be identified. The same RL agents are used to control the robot under the direction of the planning, enabling long-range navigation. We use the Probabilistic Roadmaps (PRMs) for the sampling-based planner. The RL agents are constructed using feature-based and deep neural net policies in continuous state and action spaces. We evaluate PRM-RL on two navigation tasks with non-trivial robot dynamics: end-to-end differential drive indoor navigation in office environments, and aerial cargo delivery in urban environments with load displacement constraints. These evaluations included both simulated environments and on-robot tests. Our results show improvement in navigation task completion over both RL agents on their own and traditional sampling-based planners. In the indoor navigation task, PRM-RL successfully completes up to 215 meters long trajectories under noisy sensor conditions, and the aerial cargo delivery completes flights over 1000 meters without violating the task constraints in an environment 63 million times larger than used in training.
So, when I say "I teach robots to learn" ... that's what I do.
-the Centaur