Hey folks! I am proud to announce the Workshop on Unsolved Problems in Social Robot Navigation, held at the Robotics, Science and Systems Conference in the Netherlands (roboticsconference.org). We are scheduled for 130 pm and will have several talks, spotlight papers, a poster session and discussion.
I'm an organizer for this one, but I'll only be able to attend virtually due to my manager (me) telling me I'm already going to enough conferences this year, which I am. So I will be managing the virtual Zoom, which you can sign up for at our website: https://unsolvedsocialnav.org/
After that, hopefully the next things on my plate will only be Dragon Con, Milford and 24 Hour Comics Day!
-the Centaur
Pictured: Again, from the archives, until I fix the website backend.
Today is Embodied AI #5, running Tuesday, June 18 from 8:50am to 5:30pm Pacific in conjunction with CVPR 2024's workshop track on Egocentric & Embodied AI.
Here's how you can attend if you're part of the CVPR conference:
The physical workshop will be held in meeting room Summit 428.
The physical poster session will be held in room Arch 4E posters 50-81.
The workshop will also be on Zoom for CVPR virtual attendees.
Remote and in-person attendees are welcome to ask questions via Slack:
You can see our whole schedule at https://embodied-ai.org/, but, in brief, we'll have six invited speakers, two panel discussions, two sessions on embodied AI challenges, and a poster session!
Going to crash early now so I can tackle the day tomorrow!
-the Centaur
Pictured: More from the archives, as I ain't crackin' the hood open on this website until EAI#5 is over.
The Embodied AI Workshop is coming up this Tuesday, starting at 8:50am, and I am busy procrastinating on my presentation(s) by trying to finish all the OTHER things which need to be done prior to the workshop.
One of the questions my talk raises is what ISN'T embodied AI. And the simplest way I can describe it is that if you don't have to interact with an environment, it isn't embodied.
But it's a static problem. Recognizing things in the image doesn't change things in the image. But in the real world, you cannot observe things without affecting them.
This is a fundamental principle that goes all the way down to quantum mechanics. Functionally, we can ignore it for certain problems, but we can never make it go away.
So, classical non-interactive learning is an abstraction. If you have a function which goes from image to cat, and the cat can't whap you back for getting up in its bidnes, it isn't embodied.
-the Centaur
Pictured: Gabby, God rest his fuzzy little soul, and Loki, his grumpier cousin.
So, as I've said, Embodied AI is just around the corner. But what is this workshop about? Embodied AI, of course! It says so on the tin.
But the key thing that makes "embodied AI" different from computer vision is that you must interact with an environment; the key thing that makes "embodied AI" different from robotics is that technically it doesn't need to be a real physical environment, as long as the environment is dynamic and there are consequences for actions.
SO, we will have speakers talking about embodied navigation, manipulation, and vision; generative AI to create environments for embodied agents; augmented reality; humanoid robots; and more.
Okay, now I really am going to crash because I have to fly tomorrow.
Onward!
-the Centaur
Pictured: An e-stop (emergency stop) button from a robot. Looks a little jury-rigged there, Chester.
Ok, the image is from ICRA, but I am still traveling, and have not fixed the problem on the website backend. BUT, Embodied AI is this coming Tuesday, so please drop in if you are at CVPR!
More later, I had several long days at the customer site and I am going to go crash now.
Back at Con Carolinas for day two (but once again images from the archives while my blog is getting updated in the background).
Today I was on a lively panel about the "Trials and Tribulations of AI" and if there's anything I could take away from that, it would be that "modern AIs do not check their work, so if you use them, you have to."
There's a whole debate on whether they're "really intelligent" and you probably can bet where I come down on that - or maybe you can't; here goes:
Yes, modern AI's are "artificial intelligence" - they literally are what that phrase was invented to describe.
No, modern AI's are not artificial general intelligence (AGI) - yet - and I can point you to a raft of papers describing either the limitations of these systems or what is needed for a full AGI.
Yes, they're doing things we would normally describe as intelligent, but ...
No, they're doing "thinking on a rocket sled", facing backward, tossing words on the track in a reverse of the Wallace and Gromit track-laying meme, unable to check or correct their own work.
These systems "hallucinate", just like humans are mistaken and make things up, but do so in ways alien to human thought, so if we use them in areas we can't check their work, we must do so with extreme caution.
And then there's the whole RAFT of ethics issues which I will get to another day.
Next up: "Neurodivergence and Writing" at 6:30pm, and "Is THAT even POSSIBLE" at 9:30pm!
Onward!
-the Centaur
Pictured: NOT Con Carolinas - I think this was Cafe Intermezzo.
Journaling: Today's Event: Con Carolinas. Today's Exercise, 30 pushups, planning a walk later today. Today's Drawing: finished one five three yesterday, will tackle one five four after I tackle my fix-my-roof thing.
There's an ongoing debate over whether human emotions are universal: I, like many researchers, think that there was solid work done by Ekman back in the day that demonstrated this pretty conclusively with tribes with little Western contact, but some people seem determined to try to pretend that evidence can be made not to exist once it's been collected, if you just argue loudly enough about how you think it's wrong.
(The evidence is wrong?)
Yet my cat can look surprised, or scared, or angry, or alarmed, or content, or curious. It's fairly well established that some emotions, like the self-conscious ones of shame or pride, have highly variable, culturally-determined expressions (if they have consistent expressions at all). But when animals very different from us can still communicate emotions, it's hard to believe none of it is universal.
(The evidence is wrong? What's wrong with you people?)
-the Centaur
P.S. If you subscribe to the anthropic fallacy fallacy, please do not bother to tell me that I'm falling into the anthropic fallacy, because you're the one trapped in a fallacy - sometimes surprise is just surprise, just like a heart is still a heart when that heart is found an animal, and not a "deceptively heart-like blood pump."
Pictured: Loki, saying, "What, you expect me to do something? I'm a cat. I was busy, sleeping!"
Please send us what you've got! Just between you and me and the fencepost, if we get about 7+/-2 more submissions, we'll have enough to call it done for the year and won't need to extend the CFP, so we can get on with reviewing the papers and preparing for the workshop. So please submit!
-the Centaur
Pictured: the very nice logo for the Embodied AI Workshop, a joint effort of me, my co-organizer Claudia, and I think one of Midjourney or DALL-E. Yes, there's generative AI in there, but it took a good bit of prompting to get the core art, and lot of work in Photoshop after that to make it usable.
Our call for papers is still open at https://embodied-ai.org/#call-for-papers through May 4th! We're particularly interested in two-page abstracts on the theme of the workshop:
Still hanging in there apparently - we made it to 100 blogposts this year without incidents. Taking care of some bidness today, please enjoy this preview of the t-shirts for the Embodied Artificial Intelligence Workshop. Still trying out suppliers - the printing on this one came out grey rather than white.
Perhaps we should go whole hog and use the logo for the workshop proper, which came out rather nice.
-the Centaur
Picture: Um, I said it, a prototype t-shirt for EAI#5, and the logo for EAI#5.
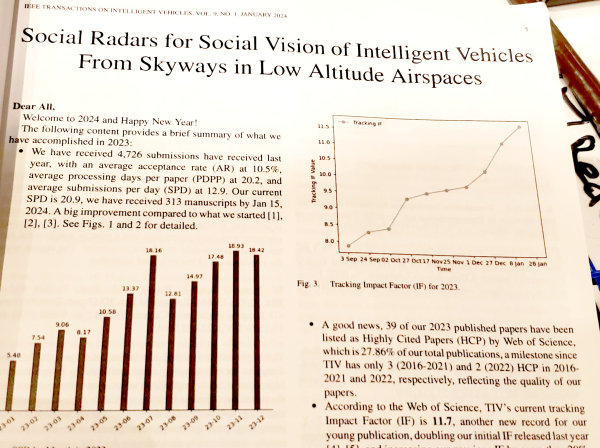
What you see there is ONE issue of the journal IEEE Transactions on Intelligent Vehicles. This single issue is two volumes, over two hundred articles, comprising three THOUSAND pages.
I haven't read the issue - it came in the mailbox today - so I can't vouch for the quality of the articles. But, according to the overview article, their acceptance rate is down near 10%, which is pretty selective.
Even that being said, two hundred articles seems excessive. I don't see how this is serving the community; you can't read two hundred papers, nor skim two hundred abstracts to see what's relevant - at least, not in a timely fashion. Heck, you can't even fully search that, as some articles might use different terminology for the same thing (e.g., "multi-goal reinforcement learning" for "goal-conditioned reinforcement learning" or even "universal value function approximators" for essentially the same concept).
And the survey paper itself needs a little editing. The title appears to be a bit of a word salad, and the first bullet point duplicates words ("We have received 4,726 submissions have received last year.") I just went over one of my own papers with a colleague, and we found similar errors, so I don't want to sound too harsh, but I still think this needed a round of copyedits - and perhaps needs to be forked into several more specialized journals.
Or ... hey ... it DID arrive on April 1st. You don't think ...
-the Centaur
Pictured: the very real horse-choking tome that is the two volumes of the January 2024 edition of TIV, which is, as far as I can determine, not actually an April Fool's prank, but just a journal that is fricking huge.
Thank goodness! At last, I'm happy to announce the Fifth Annual Embodied AI Workshop, held this year in Seattle as part of CVPR 2024! This workshop brings together vision researchers and roboticists to explore how having a body affects the problems you need to solve with your mind.
This year's workshop theme is "Open-World Embodied AI" - embodied AI when you cannot fully specify the tasks or their targets at the start of your problem. We have three subthemes:
Embodied Mobile Manipulation: Going beyond our traditional manipulation and navigation challenges, this topic focuses on moving objects through space at the same time as moving yourself.
Generative AI for Embodied AI: Building datasets for embodied AI is challenging, but we've made a lot of progress using "synthetic" data to expand these datasets.
Language Model Planning: Lastly but not leastly, a topic near and dear to my heart: using large language models as a core technology for planning with robotic systems.
The workshop will have six speakers and presentations from six challenges, and perhaps a sponsor or two. Please come join us at CVPR, though we also plan to support hybrid attendance.
Presumably, the workshop location will look something like the above, so we hope to see you there!
-the Centaur
Pictured: the banner for EAI#5, partially done with generative AI guided by my colleague Claudia Perez D'Arpino and Photoshoppery done by me. Also, last year's workshop entrance.
Now that I’m an independent consultant, I have to track my hours - and if you work with a lot of collaborators on a lot of projects like I do, it doesn’t do you much good to only track your billable hours for your clients, because you need to know how much time you spend on time tracking, taxes, your research, conference organization, writing, doing the fricking laundry, and so on.
So, when I decided to start being hard on myself with cleaning up messes as-I-go so I won’t get stressed out when they all start to pile up, I didn’t stop time tracking. And I found that some tasks that I thought took half an hour (blogging every day) took something more like an hour, and some that I thought took only ten minutes (going through the latest bills and such) also took half an hour to an hour.
We’re not realistic about time. We can’t be, not just as humans, but as agents: in an uncertain world where we don’t know how much things will cost, planning CANNOT be performed correctly unless we consistently UNDER-estimate the cost or time that plans will take - what’s called an “admissible heuristic” in artificial intelligence planning language. Overestimation leads us to avoid choices that could be the right answers.
So we “need” to lie to ourselves, a little bit, about how hard things are.
But it still sucks when we find out that they are pretty fricking hard.
-the Centaur
P.S. This post, and some of the associated research and image harvesting, I expected to take 5 minutes. It took about fifteen. GO figure. Pictured: the "readings" shelves, back from the days when to get a bunch of papers on something you had to go to the library and photocopy them, or buy a big old book called "Readings in X" and hope it was current enough and comprehensive enough to have the articles you needed - or to attend the conferences themselves and hope you found the gold among all the rocks.
It's hard to believe nowadays, but the study of psychology for much of the twentieth century was literally delusional. The first half was dominated by behaviorism, a bad-faith philosophy of psychology - let's not stoop to calling it science - which denied the existence of internal mental states. Since virtually everyone has inner mental life, and it's trivial to design an experiment which relies on internal mental reasoning to produce outcomes, it's almost inconceivable that behaviorism lasted as long as it did; but, it nevertheless contributed a great understanding of stimulus-response relationships to our scientific knowledge. That didn't mean it wasn't wrong, and by the late twentieth century, it had been definitively refuted by cognitive architecture studies which modeled internal mental behavior in enough detail to predict what brain structures were involved with different reasoning phenomena - structures later detected in brain scans.
Cognitive science had its own limits: while researchers such as myself grew up with a very broad definition of cognition as "the processes that the brain does when acting intelligently," many earlier researchers understood the "cognitive" in "cognitive psychology" to mean "logical reasoning". Emotion was not a topic which was well understood, or even well studied, or even thought of as a topic of study: as best I can reconstruct it, the reasoning - such as it was - seems to have been that since emotions are inherently subjective - related to a single subject - then the study of emotions would also be subjective. I hope you can see that this is just foolish: there are many things that are inherently subjective, such as what an individual subject remembers, which nonetheless can be objectively studied across many individual subjects, to illuminate solid laws like the laws of recency, primacy, and anchoring.
Now, in the twenty-first century, memory, emotion and consciousness are all active areas of research, and many researchers argue that without emotions we can't reason properly at all, because we become unable to adequately weigh alternatives. But beyond the value contributed by those specific scientific findings is something more important: the general scientific understanding that our inner mental lives are real, that our feelings are important, and that our lives are generally better when we have an affective response to the things that happen to us - in short, that our emotions are what make life worth living.
Still working through the Goldman book, which has the inspirational quote: "I hope you wear this book out from overuse!" And that's what you need when you're practicing!
-the Centaur
P.S. My wife and I were talking about learning skills, and she complained that she hadn't quite gotten what she wanted to out of a recent set of books. It occurred to me that there are two situations in which reading books about a skill doesn't help you:
It can be you haven't yet found the right book, course or teacher that breaks it down in the right way (for me in music, for example, it was "Understanding the Fundamentals of Music" which finally helped me understand the harmonic progression, the circle of fifths, and scales, and even then I had to read it twice).
It can be because you're not doing enough of the thing to know the right questions to ask, which means you may not recognize the answers when they're given to you.
Both of these are related to Vygotsky's Zone of Proximal Development - you can most easily learn things that are related to what you already know. Without a body of practice at a skill, reading up on it can sometimes turn into armchair quarterbacking and doesn't help you (and can sometimes even hurt you); with a body of practice, it turns into something closer to an athlete watching game footage to improve their own game.
So! Onward with the drawing. Hopefully some of the drawing theory will stick this time.
Okay, I'm going to start out with the best of the images that I produced trying to create Porsche the Centaur using ChatGPT's DALL-E interface. The above is ... almost Porsche, though her ears are too high (centaurs in the Alliance universe have ears a little more like an elf, but mobile like a dog's). And, after some coaxing, the ChatGPT / DALL-E hybrid managed to produce a halfway decent character sheet:
But both of these images came after several tries. And when I tried to get ChatGPT / DALL-E to generate a front and back view of the same character sheet, it just disintegrated into random horse and human parts:
Similarly, the initial centaur image came only after many prompt tweaks and false starts, like this one:
There are legitimate questions about whether the current round of AI art generators were trained on data taken without permission (they almost certainly were), whether they could displace human artists (they almost certainly will), and whether they will have destructive effects on human creativity (the jury is out on this one, as some forms of art will wane while new forms of art will wax).
But never let anyone tell you they've worked out all the bugs yet. These systems are great renderers at the image patch level, but their notion of coherence leaves a lot to be desired, and their lack of structural knowledge means their ability to creatively combine is radically limited to surface stylistics.
One day we'll get there. But it will take a lot of work.
When I was a kid, I read an article by Isaac Asimov complaining that the pace of scientific publication had become so great that he couldn't possibly keep up. When I was an adult, I realized that the end of the article - in which he claimed that if you heard panting behind his office door it was because he was out of breath from trying to read the scientific literature - was a veiled reference to masturbation. Yep, Isaac is the Grand Dirty Old Man of science fiction, and, man, we love you, but, damn, sometimes, you needed a filter.
Well, the future is now, and the story is repeating itself - sans Isaac's ending; my regular fiction is a touch blue so there's no need for my blog to get prurient. I'm a robotics researcher turned consultant, focusing on, among a kazillion other things, language model planning - robots using tools like ChatGPT to write their own programs. As part of this, I'm doing research - market research on AI and robotics, general research on the politics of AI, and technical research on language models in robotics.
A good buddy from grad school is now a professor, and he and I have restarted a project from the 90's on using stories to solve problems (the Captain's Advisory Tool, using Star Trek synopses as a case-base, no joke). And we were discussing this problem: he's complaining that the pace of research has picked up to the point where he can no longer keep up with the literature. So it isn't just me.
But the best story yet on how fast things are changing? Earlier this month, I was going through some articles on large language models my research - and a new announcement came out while I was still reading the articles I had just collected that morning.
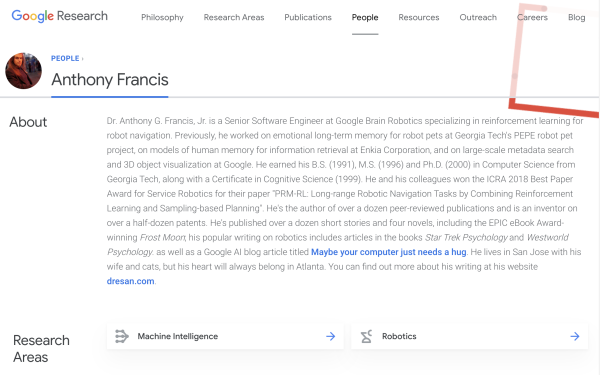
The above is a screenshot of my Google Research profile, which presumably one day (perhaps March 31st, my "official" last day) will become a dead link. After that, you may take a look at the Historical Documents in the form of a cached PDF of a printout of the page.