
When you've got a lot to do, sometimes it's tempting to just "power through it" - for example, by extending a meeting time until all the agenda items are handled. But this is just another instance of what's called "hero programming" in the software world, and while sometimes it's necessary (say, the day of a launch) it isn't a sustainable long-term strategy, and will incur debts that you can't easily repay.
Case in point, for the Neurodiversiverse Anthology, my coeditor and I burned up our normally scheduled meeting discussing, um, scheduling with the broader Thinking Ink team, so we added a spot meeting to catch up. We finalized the author and artist contracts, we developed guidance for the acceptance and rejection letters, and did a whole bunch of other things. It felt very productive.
But, all in all, a one hour meeting became three and a half, and I ended up missing two scheduled meetings because of that. The meetings hadn't yet landed on the calendar - one because we were still discussing it via email, and the other because it was a standing meeting out of my control. But because our three and a half hour meeting extended over the time we were supposed to follow up and set the actual meeting time, we never set that time, and when I was playing catch up later that evening, I literally spaced on what day of the week it was, and didn't notice the other meeting had started until it was over.
All that's on me, of course - it's important to put stuff on the calendar as soon as possible, including standing meetings, even if the invite is only for you, and I have no-one else to blame for that broken link in the chain. And both I and my co-editor agreed to (and wanted to) keep "powering through it" so we didn't have to schedule a Saturday meeting. But, I wonder: did my co-editor also have cascading side effects due to this longer meeting? How was her schedule impacted by this?
Overall, this is an anthology, and book publishing has long and unexpectedly complex and tight schedules: if we don't push to get the editing done ASAP, we'll miss our August publishing window. But it's worth remembering that we need to be kind to ourselves and realistic about our capabilities, or we'll burn out and still miss our window.
That happened to me once in grad school - on what I recall was my first trip to the Bay Area, in fact. I hadn't gotten as much done on my previous internship, and started trying to "power through it" to get a lot done from the very first week, putting in super long hours. I started to burn out the very first weekend - I couldn't keep the pace. Nevertheless, I kept trying to push, and even took on new projects, like the first draft of the proposal for the Personal Pet (PEPE) robotic assistant project.
In one sense, that all worked out: my internship turned into a love of the Bay Area, where I lived for ~16 years of my life; the PEPE project led to another internship in Japan, to co-founding Enkia, to a job at Google, and ultimately to my new career in robotics.
But, in another sense, it didn't: I got RSI from a combination of typing every day for work, typing every night for the proposal, and blowing off steam from playing video games when done. I couldn't type for almost nine months, during the writing of my PhD thesis, which I could not stop at, and had to learn to write with my left hand. I was VERY lucky: I know some other people in grad school with permanent wrist damage.
"Powering through it" isn't sustainable, and while it can lead to short-term gains and open long-term doors, can lead to short-term gaffes and long-term (or even permanent) injuries. That's why it's super important to figure out how to succeed at what you're doing by working at a sustainable pace, so you can conserve your "powering through it" resources for the times when you're really in the clinch.
Because if you don't save your resources for when you need them, you can burn yourself out along the way, and still fail despite your hard work - perhaps walking away with a disability as a consolation prize.
-the Centaur
Pictured: Powering through taking a photograph doesn't work that well, does it?











 At first this looked like a lost cause: Scrivener depended on Mac OS X's text widgets, which themselves implement a nonstandard text interface (fanboys, shut up, sit down: you're overruled. case in point: Home and End. I rest my case), and worse, depend on the OS even for the keyboard shortcuts, which require the exact menu item. But the menu item for list bullets actually was literally a bullet, which normally isn't a text character in most programs; you can't access it. But as it turns out, in Scrivener, you can. I was able to insert a bullet, find the bullet character, and even create a keyboard shortcut for it. And it did what it was supposed to!
At first this looked like a lost cause: Scrivener depended on Mac OS X's text widgets, which themselves implement a nonstandard text interface (fanboys, shut up, sit down: you're overruled. case in point: Home and End. I rest my case), and worse, depend on the OS even for the keyboard shortcuts, which require the exact menu item. But the menu item for list bullets actually was literally a bullet, which normally isn't a text character in most programs; you can't access it. But as it turns out, in Scrivener, you can. I was able to insert a bullet, find the bullet character, and even create a keyboard shortcut for it. And it did what it was supposed to!


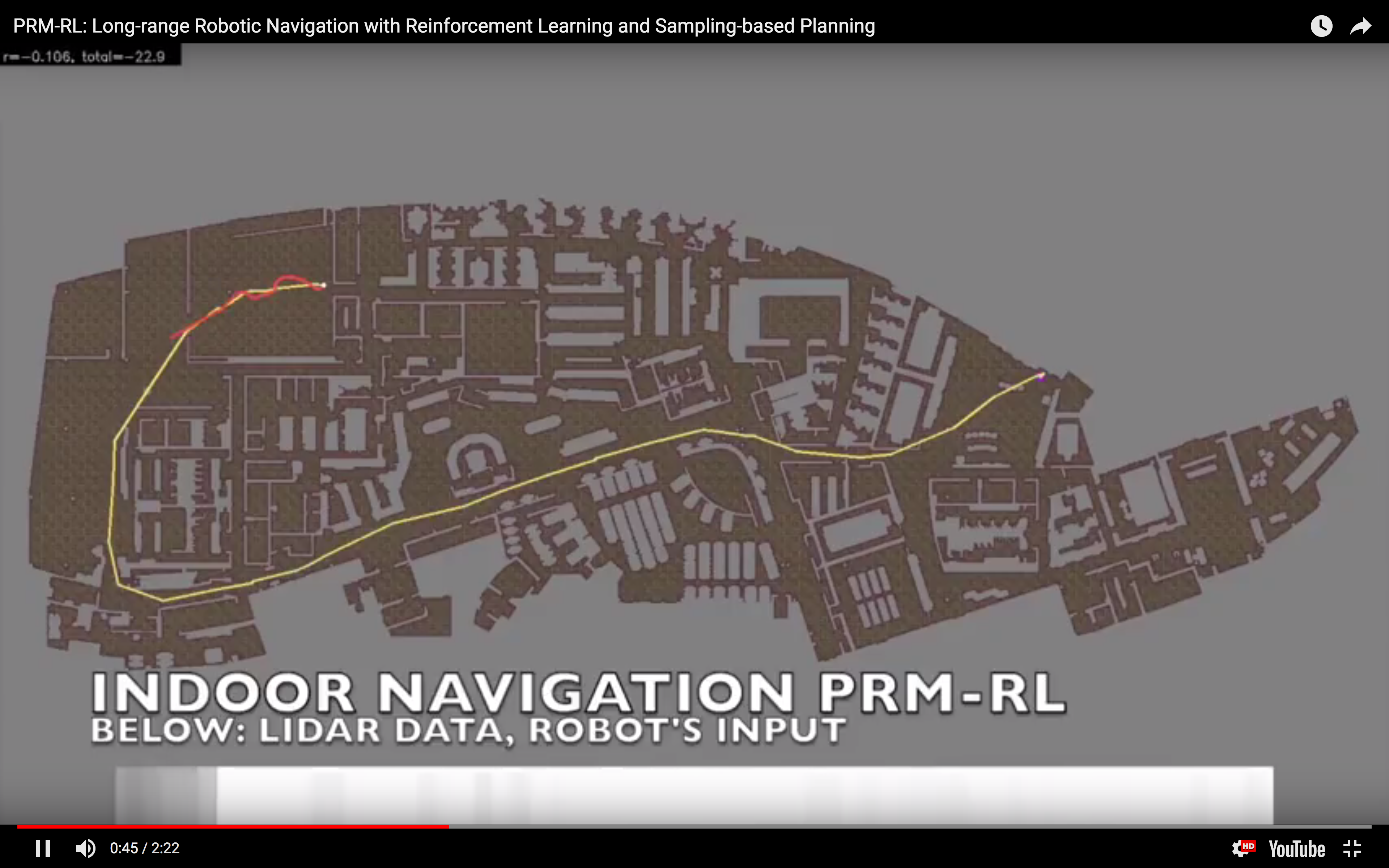 I often say "I teach robots to learn," but what does that mean, exactly? Well, now that one of the projects that I've worked on has been announced - and I mean, not just on
I often say "I teach robots to learn," but what does that mean, exactly? Well, now that one of the projects that I've worked on has been announced - and I mean, not just on 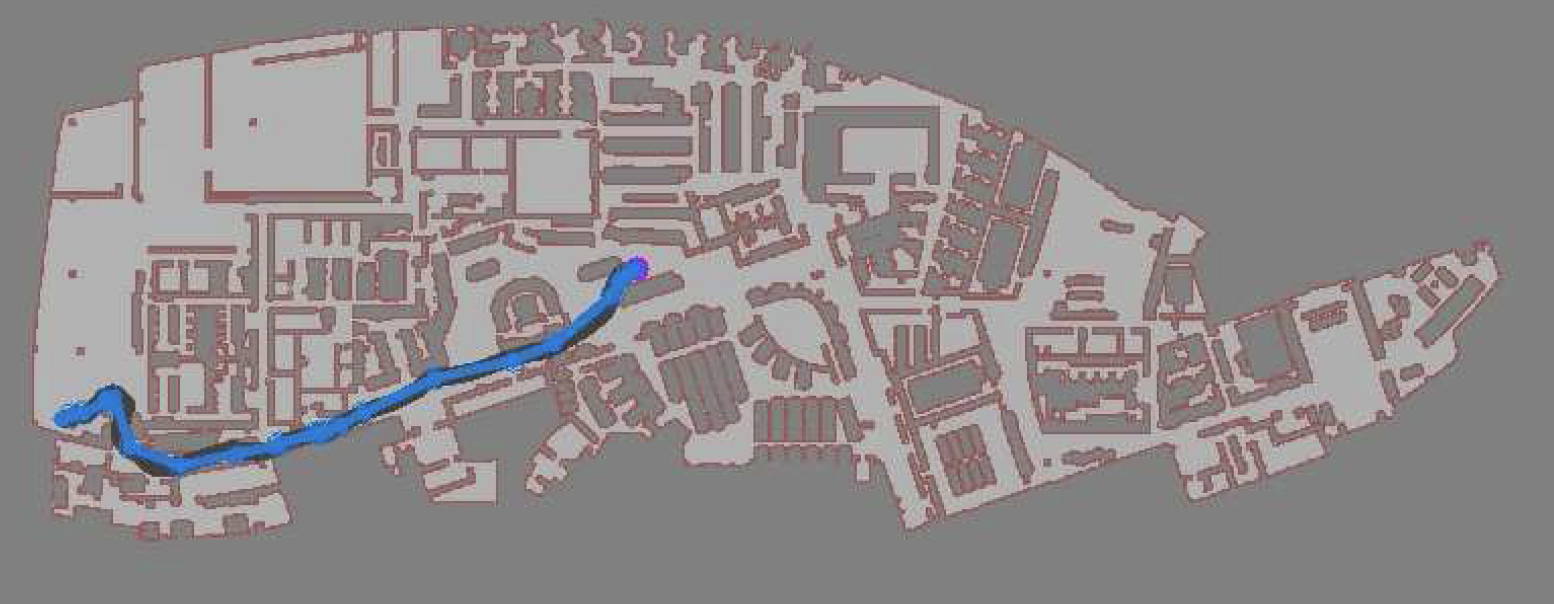 In simulation, our agent could traverse hundreds of meters using the PRM-RL approach, doing much better than a "straight-line" local planner which was our default alternative. While I didn't happen to have in my back pocket a hundred-meter-wide building instrumented with a mocap rig for our experiments, we were able to test a real robot on a smaller rig and showed that it worked well (no pictures, but you can see the map and the actual trajectories below; while the robot's behavior wasn't as good as we hoped, we debugged that to a networking issue that was adding a delay to commands sent to the robot, and not in our code itself; we'll fix this in a subsequent round).
In simulation, our agent could traverse hundreds of meters using the PRM-RL approach, doing much better than a "straight-line" local planner which was our default alternative. While I didn't happen to have in my back pocket a hundred-meter-wide building instrumented with a mocap rig for our experiments, we were able to test a real robot on a smaller rig and showed that it worked well (no pictures, but you can see the map and the actual trajectories below; while the robot's behavior wasn't as good as we hoped, we debugged that to a networking issue that was adding a delay to commands sent to the robot, and not in our code itself; we'll fix this in a subsequent round).
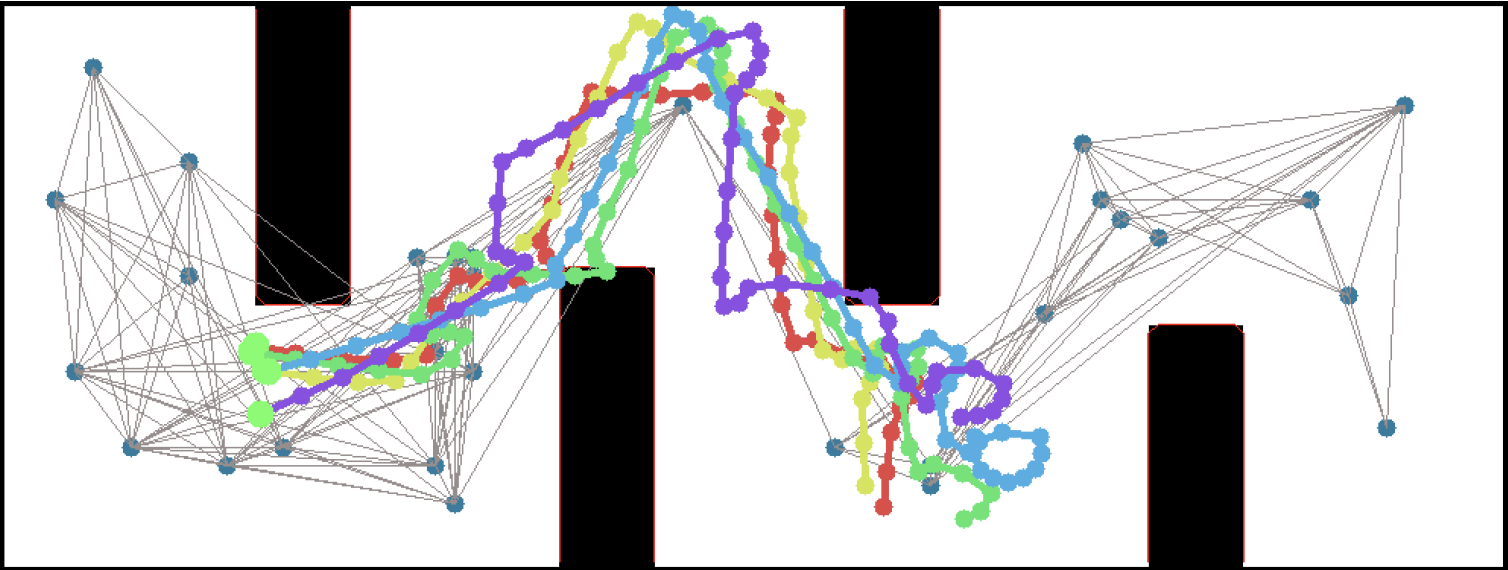 This work includes both our group working on office robot navigation - including Alexandra Faust, Oscar Ramirez, Marek Fiser, Kenneth Oslund, me, and James Davidson - and Alexandra's collaborator Lydia Tapia, with whom she worked on the aerial navigation also reported in the paper. Until the ICRA version comes out, you can find the preliminary version on arXiv:
This work includes both our group working on office robot navigation - including Alexandra Faust, Oscar Ramirez, Marek Fiser, Kenneth Oslund, me, and James Davidson - and Alexandra's collaborator Lydia Tapia, with whom she worked on the aerial navigation also reported in the paper. Until the ICRA version comes out, you can find the preliminary version on arXiv:
 So one of the things I like to do each year, as part of my traditional visit to family over the holidays, is to drop in on a Panera Bread, pull out my notebook, review my plans for the previous year, and make plans for the new one.
As of the 7th of January, I still haven't done this yet.
Shit happened last year. Good shit, such as really getting serious about teaching robots to learn; bad shit, such as serious illnesses in the pets in our family; and ugly shit which I'm not going to talk about until the final contracts are signed and everyone agrees everything is hunky and dory. And much of this went down just before the holidays, and once the holidays started, I cared a lot more about spending time with family and friends than sitting by myself in a Panera. (In all fairness, the holidays were easier when I lived in Atlanta and came up to see family many times a year, as opposed to only occasionally).
So one of the things I like to do each year, as part of my traditional visit to family over the holidays, is to drop in on a Panera Bread, pull out my notebook, review my plans for the previous year, and make plans for the new one.
As of the 7th of January, I still haven't done this yet.
Shit happened last year. Good shit, such as really getting serious about teaching robots to learn; bad shit, such as serious illnesses in the pets in our family; and ugly shit which I'm not going to talk about until the final contracts are signed and everyone agrees everything is hunky and dory. And much of this went down just before the holidays, and once the holidays started, I cared a lot more about spending time with family and friends than sitting by myself in a Panera. (In all fairness, the holidays were easier when I lived in Atlanta and came up to see family many times a year, as opposed to only occasionally).
 But I can recommend trying to do a yearly review. One year I decided to list what I wanted to do, both in the immediate future, in the coming year, in the coming 5 years, and in my life; and the next year, almost by chance, I sat down in the same Panera to review it. That served me well for more than a decade, and I find that even trying to do it helps me feel more focused and refreshed.
And so that's precisely what I tried to do yesterday. I didn't accomplish it - I still haven't managed to "clear the thickets" of my TODO lists to get to the actual yearly plan, and I miss being able to take a whole afternoon at Panera doing this - but I did the next best thing, sitting myself down to a nice "reboot" dinner and treating myself to a showing of Star Wars: The Last Jedi.
As someone said (a reference I read recently, but have been unable to find) the very act of doing something daily centers the mind.
But I can recommend trying to do a yearly review. One year I decided to list what I wanted to do, both in the immediate future, in the coming year, in the coming 5 years, and in my life; and the next year, almost by chance, I sat down in the same Panera to review it. That served me well for more than a decade, and I find that even trying to do it helps me feel more focused and refreshed.
And so that's precisely what I tried to do yesterday. I didn't accomplish it - I still haven't managed to "clear the thickets" of my TODO lists to get to the actual yearly plan, and I miss being able to take a whole afternoon at Panera doing this - but I did the next best thing, sitting myself down to a nice "reboot" dinner and treating myself to a showing of Star Wars: The Last Jedi.
As someone said (a reference I read recently, but have been unable to find) the very act of doing something daily centers the mind.
 Here's to that.
-Anthony
Here's to that.
-Anthony  Not literally; we were far south of the literal fires, which just barely missed the homes of our friends. But so many other things have been going wrong that it felt like things were on fire ... so no posts for a while, sorry.
But tonight, I got to the last chapter of Dakota Frost #6, SPIRITUAL GOLD.
I will likely finish this chapter Saturday.
That makes today a good day.
Time for some cake.
-the Centaur
Pictured: a cat break with Loki. Not how things look right now, but how I feel.
Not literally; we were far south of the literal fires, which just barely missed the homes of our friends. But so many other things have been going wrong that it felt like things were on fire ... so no posts for a while, sorry.
But tonight, I got to the last chapter of Dakota Frost #6, SPIRITUAL GOLD.
I will likely finish this chapter Saturday.
That makes today a good day.
Time for some cake.
-the Centaur
Pictured: a cat break with Loki. Not how things look right now, but how I feel.
