
Once again, I’ve completed the challenge of writing 50,000 words in a month as part of the National Novel Writing Month challenges - this time, the July 2016 Camp Nanowrimo, and the next 50,000 words of Dakota Frost #5, PHANTOM SILVER!

This is the reason that I’ve been so far behind on posting on my blog - I simultaneously was working on four projects: edits on THE CLOCKWORK TIME MACHINE, writing PHANTOM SILVER, doing publishing work for Thinking Ink Press, and doing my part at work-work to help bring about the robot apocalypse (it’s busy work, let me tell you). So busy that I didn’t even blog successfully getting TCTM back to the editor. Add to that a much needed old-friends recharge trip to Tahoe kicking off the month, and I ended up more behind than I’ve ever been … at least, as far as I’ve been behind, and still won:
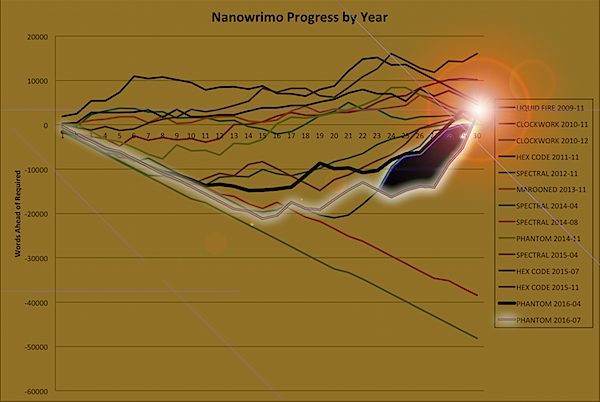
What did I learn this time? Well, I can write over 9,000 words a day, though the text often contains more outline than story; I will frequently stop and do GMC (Goal Motivation Conflict) breakdowns of all the characters in the scene and just leave it in the document as paragraphs of italicized notes, because Nano - I can take it out later, its word count now now now! That’s how you get five times a normal word count in a day, or 500+ times the least productive day in which I actually wrote something.
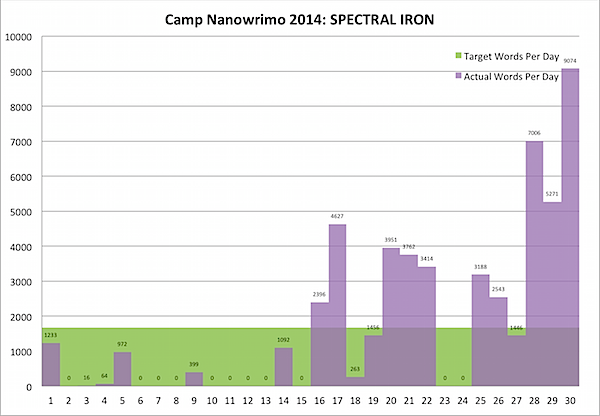
Also, I get really really really sloppy - normally I wordsmith what I write as I write, even in Nano - but that’s when I have the luxury of writing 1000-2000 words a day. When I have to write 9000, I write things like "I want someoent bo elive this whnen ai Mideone” and just keep going, knowing that I can correct the text later to “I want someone to believe this when I am done,” and, more importantly, can use the idea behind that text to craft a better scene on the next draft (in this case, Dakota’s cameraman Ron is filming a bizarre event in which someone’s life is at stake, and when challenged by a bystander he challenges back, saying that he doesn’t have any useful role to fill, but he can at least document what’s happening so they’ll all be believed later).
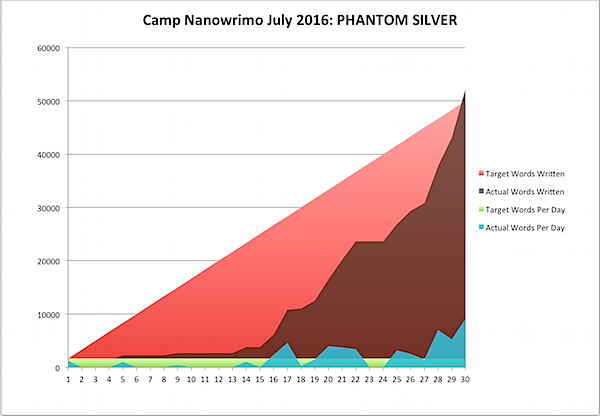
The other thing is, what I am starting to call The Process actually seems to work. I put characters in situations. I think through how they would react, using Goal Motivation Conflict to pull out what they want, why they want it, and why they can’t get it (a method recommended by my editor Debra Dixon in her GMC book). But the critical part of my Process is, when I have to go write something that I don’t know, I look it up - in a lot of detail. Yes, Virginia, even when I was writing 9,000+ words a day, I still went on Wikipedia - and I don’t regret it. Why? Because when I’m spewing around trying to make characters react like they’re in a play, the characters are just emoting, and the beats, no matter how well motivated, could get replaced by something else.

But when it strikes me that the place my characters area about visit looks like a basilica, I can do more than just write “basilica.” I can ask myself why I chose that word. I can look up the word “basilica” on Apple’s Dictionary app. I can drill through to famous basilicas like the Basilica of Saint Peter. I can think about how this place will be different from that, and start pulling out telling details. I can start to craft a space, to create staging, to create an environment that my characters can react to. Because emotions aren’t just inside us, or between us; they’re for something, for navigating this complex world with other humans at our side. If a group of people argues, no matter how charged, it’s just a soap opera. Put them in their own Germanic/Appalachian heritage family kitchen in the Dark Corner of South Carolina, on on the meditation path near an onsen run continuously by the same family for 42 generations, and the same argument can have a completely different ambiance - and completely different reactions.
The text I wrote using my characters reacting to the past plot, or even with GMC, may likely need a lot of tweaking: the point was to get them to a particular emotional, conceptual or plot space. The text I wrote with the characters reacting to things that were real, even if it needs tweaking, often crackles off the page, even in very rough form. It’s material I won’t want to lose - more importantly, material I wouldn’t have produced, if I hadn’t pushed myself to do National Novel Writing Month.
Up next, finishing a few notes and ideas - the book is very close to done - and then diving into contracts for Thinking Ink Press, and reinforcement learning policy gradients for the robot apocalypse, all while waiting for the shoe to drop on TCTM. Keep your fingers crossed that the book is indeed on its way out!
-the Centaur












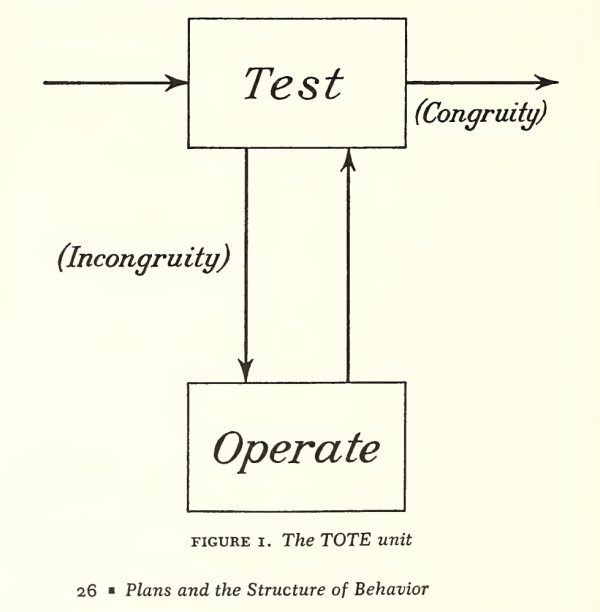





 I often say "I teach robots to learn," but what does that mean, exactly? Well, now that one of the projects that I've worked on has been announced - and I mean, not just on
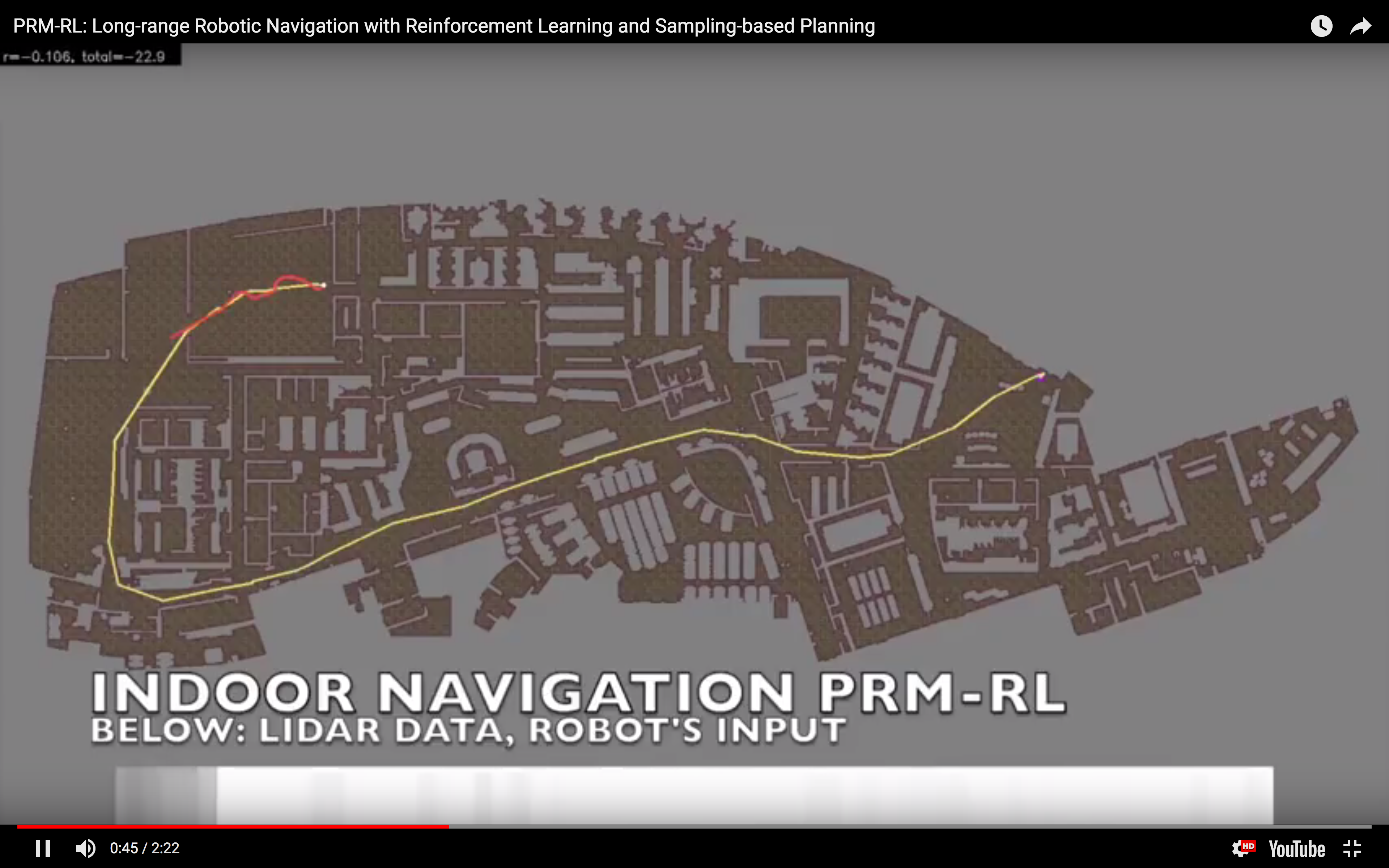
I often say "I teach robots to learn," but what does that mean, exactly? Well, now that one of the projects that I've worked on has been announced - and I mean, not just on 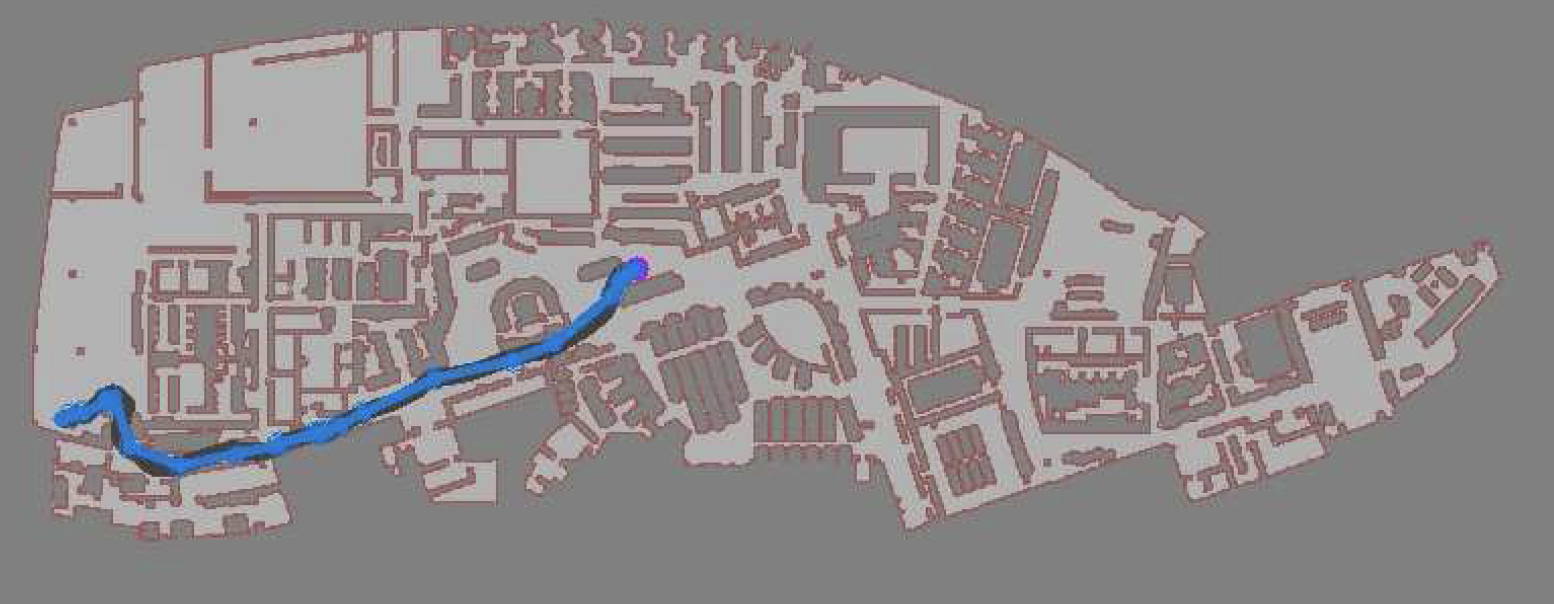 In simulation, our agent could traverse hundreds of meters using the PRM-RL approach, doing much better than a "straight-line" local planner which was our default alternative. While I didn't happen to have in my back pocket a hundred-meter-wide building instrumented with a mocap rig for our experiments, we were able to test a real robot on a smaller rig and showed that it worked well (no pictures, but you can see the map and the actual trajectories below; while the robot's behavior wasn't as good as we hoped, we debugged that to a networking issue that was adding a delay to commands sent to the robot, and not in our code itself; we'll fix this in a subsequent round).
In simulation, our agent could traverse hundreds of meters using the PRM-RL approach, doing much better than a "straight-line" local planner which was our default alternative. While I didn't happen to have in my back pocket a hundred-meter-wide building instrumented with a mocap rig for our experiments, we were able to test a real robot on a smaller rig and showed that it worked well (no pictures, but you can see the map and the actual trajectories below; while the robot's behavior wasn't as good as we hoped, we debugged that to a networking issue that was adding a delay to commands sent to the robot, and not in our code itself; we'll fix this in a subsequent round).
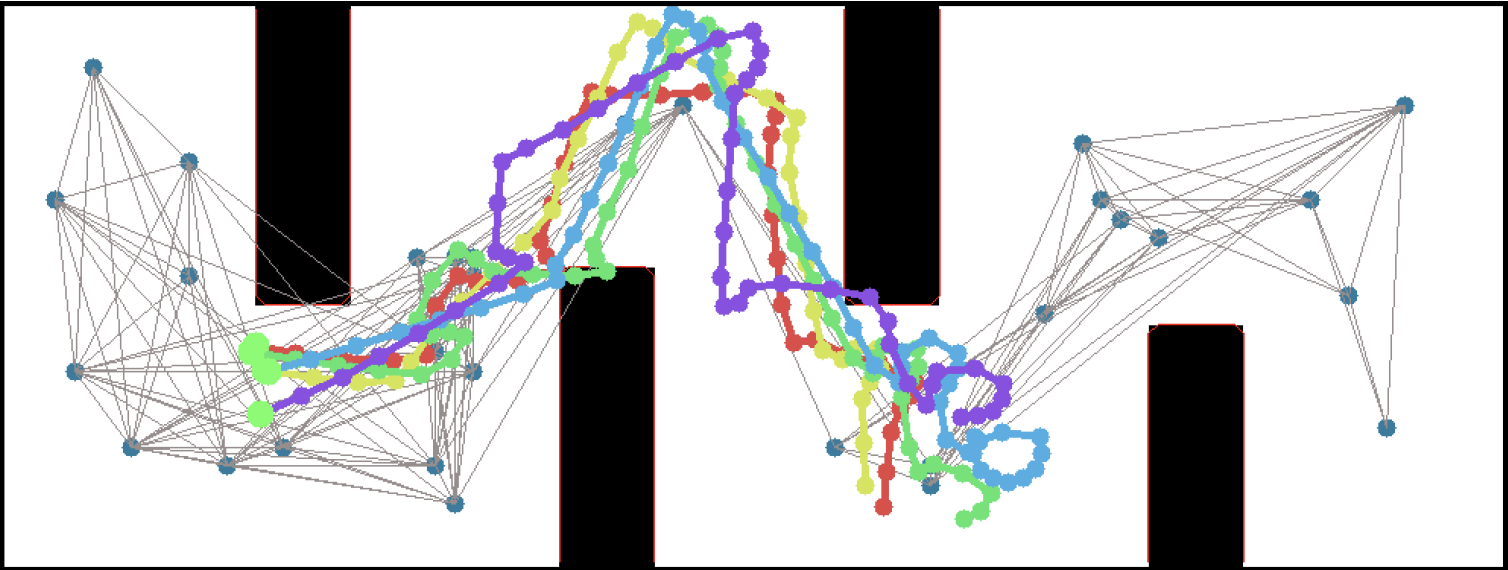 This work includes both our group working on office robot navigation - including Alexandra Faust, Oscar Ramirez, Marek Fiser, Kenneth Oslund, me, and James Davidson - and Alexandra's collaborator Lydia Tapia, with whom she worked on the aerial navigation also reported in the paper. Until the ICRA version comes out, you can find the preliminary version on arXiv:
This work includes both our group working on office robot navigation - including Alexandra Faust, Oscar Ramirez, Marek Fiser, Kenneth Oslund, me, and James Davidson - and Alexandra's collaborator Lydia Tapia, with whom she worked on the aerial navigation also reported in the paper. Until the ICRA version comes out, you can find the preliminary version on arXiv: