I'm sure this is obvious to most people who are not dumb that the key discovery of the person known as the world's greatest smarty pants might be a difficult subject, but I apparently have the dumb. I have been studying general relativity ("Einstein gravity") on and off, for twenty years, and while I get some of it, other parts still just keep breaking my head.
Like, why does time slow down when you accelerate? That's, like, almost THE key prediction of GR. The explanation seems so simple, but yet, when I try to work through the links of the chain, I just can't get it. I read the words and then try to recreate it in my little black grid-ruled notebook and end up right where I started, asking the question, "What does baffled mean?"
The current attempt involves having literally about a half-dozen books that have useful-seeming explanations of gravitational time dilation, which I am going through in quasi-parallel, trying to get a grip on the key feature which just doesn't make sense to me (why particles emitted in the roof of a rocket or elevator seem to "run fast" compared to an observer sitting on the floor).
I feel if I could just get this, then I'd have a much deeper understanding. But the understanding I do have gives me two wrong answers: one, it shouldn't work at all, or two, it's always been there in the equations, and Newton should have discovered it, but simply didn't because he didn't think of it.
Hopefully I'll get there. Wish me luck.
-the Centaur
Pictured: pound cake, almond milk, two general relativity textbooks, and buried between them the little black notebook where I'm trying to work all this out. Thanks, Albert.
Back in 1997, I drove across country for HAL 9000's birthday (yes, THAT Hal), held at the University of Illinois, Urbana-Champaign, where a friend was a graduate student. They called it the Cyberfest, and Arthur C. Clarke joined us for the first transatlantic video call at 1 frame per second.
But on the drive, I recall watching the time zones change around me. I calculated how many degrees across the Earth I had driven ... and the shift in time due to the curve around the Earth matched up.
No, it's not flat, and you cannot fake reality in any way whatsoever.
-the Centaur
Pictured: an Old Fashioned at the One Five, where we had a nice vegan meal after my urgent care visit for my broken toe.
Another key concept that I think is critically important for science and life is "getting traction." A lot of things we do as humans simply don't get us anywhere - for example, most work in philosophy. That may sound like I'm being snarky, and maybe I am, but it's a common trope that we've been discussing things like free will, the nature of time, and Zeno's paradox for thousands of years with no real resolution.
But the problem is that, contra Immanuel Kant, philosophy cannot be reduced to an enterprise that tries to answer "What can I know?" "What should I do?", "What can I hope?" and "What is a human being?" - though those questions are critically important to philosophy. Similarly, contra Ayn Rand, philosophy cannot be reduced to "Where am I?" (metaphysics), "How do I know?" (epistemology), and "What should I do?" (ethics) - though these disciplines are critically important to philosophy.
No, philosophy's job is to map the options of thought. Perennial questions like free will remain perennial because there are many ways to think about the problem and a responsible philosopher won't just attempt to "solve" it, they'll outline the different ways that we can think about it (as Daniel Dennett tried to do in Elbow Room: The Varieties of Free Will Worth Having). Like Saint Thomas Aquinas, I believe that you have free will whether you want it or not - though my argument is based on the Halting Problem - but even Aquinas admits that if your definition of free will excludes the possibility of a mechanism by which the will works, then he can't help you. So even if we reached a definitive answer to the question of free will eight hundred years ago, modern treatments cannot resist revisiting the entirety of the argument.
Leaving us feeling like we're getting nowhere.
To make progress, we need some way of moving on - some way of selecting an idea as the right one. And that can't happen from within philosophy itself - not just because I argue that "solving" isn't it's job, but because of a deeper problem that Ayn Rand calls the Primacy of Consciousness Fallacy - the idea that ideas are more important than reality. The way we think about problems does not change what is. For example, the Ship of Theseus is a famous "thought experiment in identity metaphysics" (according to Vision in the Marvel Universe) about a boat whose timbers are replaced one by one until nothing of the originals remain, raising question: is it the same boat or not? There are strong reasons to say that is, and that it isn't - but those are just options for thinking about it. It doesn't change the actual physical nature of the boat.
To get anywhere with these questions, we need to get evidence. To take a hypothetical example, if we were in a horror movie, and the fully-gutted Ship of Theseus started chasing people down to reclaim its lost timbers, we might start to suspect that it was, indeed, the same ship. Conversely, if we were in a science fiction movie, and no-one who went through a transporter ever remembered who they were, we might start to suspect that their identity was not preserved, and that a matter-energy scrambler was not a good way to transport people from point A to B no matter how much money it saved on the show's budget.
But these are hypotheticals. To really get anywhere with a real question - to get traction in the space of ideas that moves us from a set of options on to a definitive answer - you need more than an argument that convinces yourself; you to start looking for ways to get evidence that distinguishes between the options, evidence that can be shared with other people, or replicated by them, to help them make the same move.
You can see this clearly when looking at the philosophy of general relativity, which explores staggeringly speculative concepts like thunderbolts (fractures in spacetime that spread at the speed of light) and supertasks (performing infinite tasks like computing the digits of pi in one part of spacetime and reading them off in another, dilated part of spacetime, hoping to find that elusive last digit). These questions involve scenarios we can't set up and tasks we cannot perform, and it's difficult to see how they could be resolved.
But these mental explorations help us understand what directions to take in our scientific explorations. The philosopher Mach wondered whether a rotating object in an empty universe could really be said to spin. It's a challenge to set up an entire universe just to answer a hypothetical - but Mach's exploration of the problem helped Einstein formulate his theory of general relativity, which in turn had consequences that were tested the scientist Eddington in a famous expedition. Eddington traveled to photograph a solar eclipse, which showed that starlight around the sun was bent the way Einstein predicted - in turn, giving us a probable answer to Mach's question that, yes, the object would rotate with respect to itself.
Getting traction is an important part of not just science but our everyday lives. I always get suspicious when I go to the doctor and they purport to make a diagnosis without running tests to verify whether they're right. Once, when my arm was broken and the bone plate was slow to heal, I went to a parade of doctors who failed to resolve the problem over a 2 year period. Doctors at the SOAR group ordered a CAT scan, identified a gap in the bone, and scheduled an exploratory surgery, during which they found a suture left from the original surgery that had caused a bulge in the bone and the appearance of a gap. My arm was fine, and likely had been fine for 2 years - but the other doctors didn't find this out because they didn't run the test.
The necessity of getting traction is why, in programming, I hate nondeterministic builds (where sometimes it works and sometimes it doesn't) and hate debugging heisenbugs (where sometimes it fails and sometimes it doesnt). Stochastic failures - failures which happen randomly - lead you to trying things over and over again, hoping to get different results. Doing something again and expecting different results may not be the definition of insanity, and Einstein certainly didn't say it, but it's not great, and it trains you to flail.
Once I encountered this as a real debugging issue - resolving a problem with a robotic device driver for a lidar sensor (a laser radar, used to tell how close objects were to the robot). I was frustrated and thrashing with non-repeatable bugs in my program, and eventually cracked out the manufacturer's diagnostic program to see if I had a bad sensor. But the manufacturer's diagnostic also had the same problems, on more than one lidar unit, and I realized that correctly working sensors of that make and model were actually unreliable when connected to the computer we were using!
So how did I get traction when I literally couldn't trust the data coming from the sensor?
With a spreadsheet.
For each variant of the program that I tried - the original, and various fixes - I ran the program ten times, counted the successes and failures, and entered them into my spreadsheet. It very quickly became apparent that the original program almost never, whereas the best of my fixes worked seventy percent of the time. Since our experimental robots frequently needed to be rebooted multiple times on startup to fix other race conditions, we had no problem shipping "seventy percent success" as an improvement over ten percent.
Getting traction is a key part of science, engineering, and life. We can even apply it to philosophy, if we ask ourselves whether there are actual facts that help us choose between the options, or whether there are values that we hold that lead us to prefer one option over the other. In fact, many of the best philosophers produced their greatest work by taking definitive stands on one or more philosophical questions and then pursuing the implications rigorously. Some would even argue that modern physics is a kind of natural philosophy which took the stance of materialism to its logical conclusion - and then started producing fantastic empirical results by building on that stance.
So what problems in your life could you improve on if you found a way to push off from where you are?
-the Centaur
Pictured: We're fixing our roof, so we have to protect our floor. This floorpaper is actually to help our interior repair team move equipment without damaging our hardwoods, and does not have anything to do with traction, regardless of whether it looks like it's something used for that purpose.
What is science? I think about this a lot. Before I broke my notebooks apart into fine-grained projects, I used to keep an entirely separate series of notebooks just for science, as opposed to my writing and sketching, and in each science notebook I'd attempt to redefine exactly what I thought science was.
So it might surprise you that I stopped listening to a psychology audiobook when the professor said (paraphrased): "Wilhelm Wundt defined psychology as the science of mind, thus dooming it to failure, because science is based on the study of phenomena that are public, repeatable and measurable."
I literally hit eject a few seconds after hearing that, and said aloud (paraphrased), "Now, this is what people mean when they say people in the soft sciences are trying too hard to emulate the hard sciences without understanding how the hard sciences work." (There may have been a few curse words in there as well.)
Now, I said I stopped listening a few seconds later - right around the point where the professor said "psychology is defined as the study of behavior" because if the professor had that poor a grasp of what science is and of how his own science is defined, how could I trust anything else that he would say?
My friends in science, psychology is defined as the study of mind and behavior. There are plenty of well-formed psychology experiments that can be conducted that have no overt behavior at all - for example, whether a visual image causes signs of recognition in the brain as detected by a brain scanner.
Furthermore, whether something is public or not has nothing to do with with whether it can be the subject of science. Quarks are not public - they only exist in bound states - and if our theories of quarks are correct, their properties cannot be directly measured, only inferred from the behavior of particle aggregates.
Furthermore, whether something is repeatable or not is not a measure of whether it is scientific. That's an empirical question. We have reason to believe that the phenomena of genetic inheritance, thermal noise in materials, and radioactive decay are fundamentally random, and can only be predicted in the aggregate.
So what is science? Richard Feynman was fond of saying that science meant "the sole test of any idea is experiment" and I love modifying that to say "the sole test of any idea open to observation is experiment" because observation crystallizes the key distinction between mathematics, science, and speculation.
This brings us to the part I like most about the "public, repeatable, and measurable" part of the professor's definition, because while the subject of a science may not be measurable, there certainly has to be something that's actually observable, or you're dealing with mathematics or metaphysics.
And that brings us, in turn, to FOOM.
My definition of science is that it is the formal observational / operational method (FOOM) of bringing phenomena in the world in contact with modeling and experiment so those phenomena can be explained and our understanding of the phenomena in the world can be expanded. What does this mean?
Well, first off, the scientific method is formal. You may become like Thoreau and retire to a cabin to suck the marrow out of life, and you may learn a lot by doing that, and you might even write it down in a famous book that transforms many people's lives - but that's recounting your experience, and is not science.
The first step in science is observation of the world - actually, direct observation of phenomena in the world like Thoreau did - but what starts to transform it into science is formality. Formal means we bring to observation some kind of structure which enables us to collect a raw body of facts about a phenomenon.
For example, sleep researcher J. Allan Hobson recorded a dream journal over decades to start collecting a body of data that occur in dreams. Without a comparable body of data, it's impossible to say what "typically" happens in a dream and we're reduced to sharing anecdotes.
But of course, the dream journal of one particular person who happened to be a sleep researcher might not be typical - and that's where the operational part of the method. If the dream journal seemed to produce useful data, then researchers can start to develop protocols that analyze them more rigorously.
Formal observations that have been operationalized have been embedded in a set of procedures which enable the observations to be collected reliably - at which point we start calling them measurements (or more broadly evidence, if the observations are not very number-like, for example, narratives).
Science doesn't start with physicists building a two-mile-long particle accelerator to measure the charge of the electron. It starts(ish) with Ben Franklin doing some damfool thing with a kite, string, key and bottle, progresses through Michael Faraday having to instruct people on how to interpret his magnetic induction experiments, and ends with the discovery of the electron by J. J. Thompson a century and a half later.
By the time that happened, the operational methods were so good that Thompson got a read on the mass / charge ratio of the electron when he isolated it. But here's the thing: the electron itself, that is, the particle, was a discovery, not at all apparent in Franklin's time - when electricity was thought of as a fluid.
Now we have principled reasons to believe, based on public, repeatable measurements, that electrons are fundamental in the same sense that private, quantum mechanical, unmeasurable quarks are fundamental, and in the same sense that composite objects like protons, atoms, and psychology professors are not.
But we didn't get there by starting off with phenomena that were public, repeatable, and measurable. We started off wonding about a phenomenon as unpredictable as lightning, and by a centuries-long process of creating formal methods to turn observations into operationalizable measurements - which we used to craft experiments to explore the phenomena we discovered along the way, no matter how weird they were.
That's why I say that the formal observational / operational method, which I call "FOOM" in my conceptual lexicon, is the foundation we need to lay in order to subject the ideas we have to experiment. And that difficult process of reducing chaos to order while being open to surprises, to me, is the essence of science.
-the Centaur
Pictured: the Physics section of Moe's Books in Berkeley
Above is what looks like a massive anthill at the border of the "lawn" and "forest" parts of our property. It's been getting bigger and bigger over the years, and that slow growth always reminds me of Mr. Morden's comments in Babylon 5 about the Shadows' plan to make lesser races fight:
JUSTIN: "It's really simple. You bring two sides together. They fight. A lot of them die, but those who survive are stronger, smarter and better." MORDEN: "It's like knocking over an ant-hill. Every new generation gets stronger, the ant-hill gets redesigned, made better."
But the Shadows were wrong, and what we're seeing there isn't a redesigned anthill: it is a catastrophe, a multigenerational ant catastrophe caused by climate, itself brought to light by a larger, slow-motion human catastrophe caused by climate change.
Humans have farmed, built and burnt for a long time, but only now, in the dawn of the Anthropocene - that period of time where human impacts on climate start to exceed natural variation of climate itself, beginning roughly in the 1900s - have those effects really come back to bite us on a global, rather than local, scale.
For my wife and I, this took the form of fire. Fire was not new in California: friends who lived on homes on ridges complained about their high insurance costs as far back as I can remember. But more and more fires started burning across our area, forcing other friends to move away. Then three burned within five miles of our home, with no end to the drought in sight, and we decided we'd had enough.
We moved to my ancestral home, a place where water falls from the sky, aptly named Greenville. And we moved into a house whose builders knew about rain, and placed it on a hill with carefully designed drainage. They created great rolling lawns, manicured in the traditional Greenville "let's fucking force it with chemicals and lawnmowers to look like it was Astroturf" which we are slowly letting go back to nature.
In this grass, and in the absence of pesticides, the ants flourished. But this isn't precisely a natural environment: they're flourishing in an expanse of grass that is wider and more rounded than the rough, ridged forest around it. In the forest, runoff from the rains is channeled into proto-streams leading to the nearby creek; at the edge of the lawn, water from the house and lawn spills out in a flood.
Each heavy rain, the anthills building up in the sloped grass are washed to the mulch beds that mark the boundary of the forest, and there the ants start to re-build. But lighter rains can destroy these more exposed anthills, forcing them to slowly migrate back up into the grass. That had already happened here: that was no longer a live anthill, and unbeknownst to me, I was standing in its replacement.
No worries, for them or me; I noticed the anthill was dead, looked down, and moved off their territory just as the ants were swarming out of their antholes, fit to kill (or at least to annoyingly nibble). But the great red field there, as wide as a man is tall and twice as long, was not a functioning anthill: it was the accumulated wreckage of generation after generation of ant catastrophes.
In the quote, Mr. Morden was wrong: knocking over an anthill doesn't make it come back better designed. Justin got it a little better: the strongest and smartest do often survive a battle - but they walk away with scars, and sometimes the winners may just be the lucky ones. Conflict may not make people better - it can just leave scarred soldiers, wounded refugees and a destroyed landscape.
Now, the Shadows were the villains of the story, but every good villain needs a good soundbite that makes them sound at least a little bit good, and it's worth demolishing this one. "The anthill comes back better stronger and better designed" is designed to riff on the survival of the fittest - the notion that creating survival pressure will lead to stronger, smarter, and better individuals.
But evolution doesn't work that way. Those stronger, smarter, and better individuals have to have existed in the population in the first place. Evolution only leads to improvements over time at all if the variation of the population continues to yield increasingly better individuals generation after generation - and that is not at all guaranteed. The actual historical pattern is far closer to the opposite.
Now, people who should know better often claim that evolution has no direction. I think that's because there's a cartoon version of evolution where things tend to get more complex over time, and they want to replace it with another cartoon version of evolution which is blind and random - perhaps spillover from Dawkins' attempts to argue with creationists using his Blind Watchmaker idea.
But that's not how evolution works at all. Evolution does have a direction - just like gravity does. Only at the narrow level of the fundamental laws operating on idealized, homogeneous substrates can we say gravity is symmetric, or evolution is directionless. Once the scope of our investigation expands and the structure of the world gets complex - once symmetry is broken - then gravity clumps matter into planets and gives us "up", and evolution molds organisms into ecosystems and gives us "progress towards complexity".
But the direction of evolution is a lot more like the gradient of air around a planet than it is any kind of "great chain of being". Once an ecosystem exists, increased complexity provides an advantage for a small set of organisms, and as they spread into the ecosystem, a niche is created for even more complex organisms to exceed them. But, just like most of the atmosphere is closest to the surface of a planet, most of the organisms will remain the simplest ones.
Adding additional selection pressure won't give you more complex organisms: it will give you fewer of them. The more stress on the ecosystem, the harder it is for anything to survive, the size of the various niches will shrink, and even if the ecosystem still provides enough resources to support complex organisms, the size of the population that can evolve will drop, making it less likely for even more complex ones to arise - and that's assuming it doesn't get so rough that the complex organisms go extinct.
Eventually, atoms bouncing around in the atmosphere may fly off into space - just like, eventually, evolution produced a Neil Armstrong who flew to the moon. But pouring energy into the atmosphere may slough the upper layers off into space, leaving a thin remnant closest to the planet - and, so, stressing an ecosystem will not produce more astronauts; it may kill them off and leave everyone down in the muck.
Which gives us a hint to what the Shadows' real plan was. They're portrayed as an ancient learned race, so presumably they knew everything I just shared - but they're also portrayed as the villains, after all, and so they ultimately had a self-serving goal in mind. And if knocking over an anthill doesn't make it come back better designed, then their real goal was to keep kicking over anthills so they themselves would stay on top.
-the Centaur
Pictured: Me, near sunset, taking picture of what I thought was a live anthill - until I looked more closely.
Congratulations, Sir Richard Branson, on your successful space flight! (Yes, yes, I *know* it's technically just upper atmosphere, I *know* there's no path to orbit (yet) but can we give the man some credit for an awesome achievement?) And I look forward to Jeff Bezos making a similar flight later this month.
Now, I stand by my earlier statement: the way you guys are doing this, a race, is going to get someone killed, perhaps one of you guys. A rocketship is not a racecar, and moves into realms of physics where we do not have good human intuition. Please, all y'all, take it easy, and get it right.
That being said, congratulations on being the first human being to put themselves into space as part of a rocket program that they themselves set in motion. That's an amazing achievement, no-one can ever take that away from you, and maybe that's why you look so damn happy. Enjoy it!
-the Centaur
P.S. And day 198, though I'll do an analysis of the drawing at a later time.
You know, Jeff Bezos isn’t likely to die when he flies July 20th. And Richard Branson isn’t likely to die when he takes off at 9am July 11th (tomorrow morning, as I write this). But the irresponsible race these fools have placed them in will eventually get somebody killed, as surely as Elon Musk’s attempt to build self-driving cars with cameras rather than lidar was doomed to (a) kill someone and (b) fail. It’s just, this time, I want to be caught on record saying I think this is hugely dangerous, rather than grumbling about it to my machine learning brethren.
Whether or not a spacecraft is ready to launch is not a matter of will; it’s a matter of natural fact. This is actually the same as many other business ventures: whether we’re deciding to create a multibillion-dollar battery factory or simply open a Starbucks, our determination to make it succeed has far less to do with its success than the realities of the market—and its physical situation. Either the market is there to support it, and the machinery will work, or it won’t.
But with normal business ventures, we’ve got a lot of intuition, and a lot of cushion. Even if you aren’t Elon Musk, you kind of instinctively know that you can’t build a battery factory before your engineering team has decided what kind of battery you need to build, and even if your factory goes bust, you can re-sell the land or the building. Even if you aren't Howard Schultz, you instinctively know it's smarter to build a Starbucks on a busy corner rather than the middle of nowhere, and even if your Starbucks goes under, it won't explode and take you out with it.
But if your rocket explodes, you can't re-sell the broken parts, and it might very well take you out with it. Our intuitions do not serve us well when building rockets or airships, because they're not simple things operating in human-scaled regions of physics, and we don't have a lot of cushion with rockets or self-driving cars, because they're machinery that can kill you, even if you've convinced yourself otherwise.
The reasons behind the likelihood of failure are manyfold here, and worth digging into in greater depth; but briefly, they include:
The Paradox of the Director's Foot, where a leader's authority over safety personnel - and their personal willingness to take on risk - ends up short-circuiting safety protocols and causing accidents. This actually happened to me personally when two directors in a row had a robot run over their foot at a demonstration, and my eagle-eyed manager recognized that both of them had stepped into the safety enclosure to question the demonstrating engineer, forcing the safety engineer to take over audience questions - and all three took their eyes off the robot. Shoe leather degradation then ensued, for both directors. (And for me too, as I recall).
The Inexpensive Magnesium Coffin, where a leader's aesthetic desire to have a feature - like Steve Job's desire for a magnesium case on the NeXT machines - led them to ignore feedback from engineers that the case would be much more expensive. Steve overrode his engineers ... and made the NeXT more expensive, just like they said it would, because wanting the case didn't make it cheaper. That extra cost led to the product's demise - that's why I call it a coffin. Elon Musk's insistence on using cameras rather than lidar on his self-driving cars is another Magnesium Coffin - an instance of ego and aesthetics overcoming engineering and common sense, which has already led to real deaths. I work in this precise area - teaching robots to navigate with lidar and vision - and vision-only navigation is just not going to work in the near term. (Deploy lidar and vision, and you can drop lidar within the decade with the ground-truth data you gather; try going vision alone, and you're adding another decade).
Egotistical Idiot's Relay Race (AKA Lord Thomson's Suicide by Airship). Finally, the biggest reason for failure is the egotistical idiot's relay race. I wanted to come up with some nice, catchy parable name to describe why the Challenger astronauts died, or why the USS Macon crashed, but the best example is a slightly older one, the R101 disaster, which is notable because the man who started the R101 airship program - Lord Thomson - also rushed the program so he could make a PR trip to India, with the consequence that the airship was certified for flight without completing its endurance and speed trials. As a result, on that trip to India - its first long distance flight - the R101 crashed, killing 48 of the 54 passengers - Lord Thomson included. Just to be crystal clear here, it's Richard Branson who moved up his schedule to beat Jeff Bezos' announced flight, so it's Sir Richard Branson who is most likely up for a Lord Thomson's Suicide Award.
I don't know if Richard Branson is going to die on his planned spaceflight tomorrow, and I don't know that Jeff Bezos is going to die on his planned flight on the 20th. I do know that both are in an Egotistical Idiot's Relay Race for even trying, and the fact that they're willing to go up themselves, rather than sending test pilots, safety engineers or paying customers, makes the problem worse, as they're vulnerable to the Paradox of the Director's Foot; and with all due respect to my entire dot-com tech-bro industry, I'd be willing to bet the way they're trying to go to space is an oversized Inexpensive Magnesium Coffin.
-the Centaur
P.S. On the other hand, when Space X opens for consumer flights, I'll happily step into one, as Musk and his team seem to be doing everything more or less right there, as opposed to Branson and Bezos.
P.P.S. Pictured: Allegedly, Jeff Bezos, quick Sharpie sketch with a little Photoshop post-processing.
What happens when deep learning hits the real world? Find out at the Embodied AI Workshop this Sunday, June 20th! We’ll have 8 speakers, 3 live Q&A sessions with questions on Slack, and 10 embodied AI challenges. Our speakers will include:
Motivation for Embodied AI Research
Hyowon Gweon, Stanford
Embodied Navigation
Peter Anderson, Google
Aleksandra Faust, Google
Robotics
Anca Dragan, UC Berkeley
Chelsea Finn, Stanford / Google
Akshara Rai, Facebook AI Research
Sim-2-Real Transfer
Sanja Fidler, University of Toronto, NVIDIA Konstantinos Bousmalis, Google
... came up as my wife and I were discussing the "creative hangers-on form" of Stigler's Law. The original Stigler's Law, discovered by Roger Merton and popularized by Stephen Stigler, is the idea that in science, no discovery is named after its original discoverer.
In creative circles, it comes up when someone who had little or nothing to do with a creative process takes credit for it. A few of my wife's friends were like this, dropping by to visit her while she was in the middle of a creative project, describing out loud what she was doing, then claiming, "I told her to do that."
In the words of Finn from The Rise of Skywalker: "You did not!"
In computing circles, the old joke referred to the Java programming language. I've heard several variants, but the distilled version is "He thinks he invented Java because he was in the room when someone made coffee." Apparently this is a good description of how Java itself was named, down to at least one person claiming they came up with the name Java and others disputing that, even suggesting that they opposed it, claiming instead that someone else in the room was responsible - while that person in turn rejected the idea, noting only that there was some coffee in the room from Peet's.
Hail, fellow adventurers: to prove I do something more than just draw and write, I'd like to send out a reminder of the Second Embodied AI Workshop at the CVPR 2021 computer vision conference. In the last ten years, artificial intelligence has made great advances in recognizing objects, understanding the basics of speech and language, and recommending things to people. But interacting with the real world presents harder problems: noisy sensors, unreliable actuators, incomplete models of our robots, building good simulators, learning over sequences of decisions, transferring what we've learned in simulation to real robots, or learning on the robots themselves.
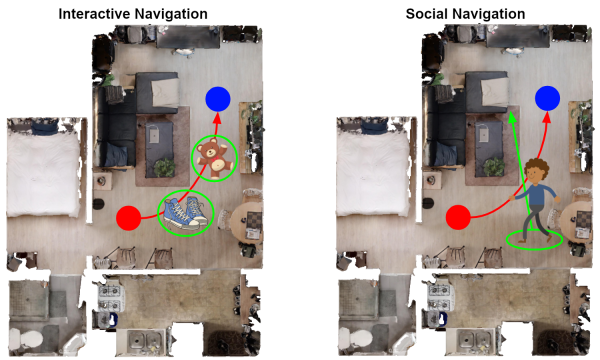
The Embodied AI Workshop brings together many researchers and organizations interested in these problems, and also hosts nine challenges which test point, object, interactive and social navigation, as well as object manipulation, vision, language, auditory perception, mapping, and more. These challenges enable researchers to test their approaches on standardized benchmarks, so the community can more easily compare what we're doing. I'm most involved as an advisor to the Stanford / Google iGibson Interactive / Social Navigation Challenge, which forces robots to maneuver around people and clutter to solve navigation problems. You can read more about the iGibson Challenge at their website or on the Google AI Blog.
Most importantly, the Embodied AI Workshop has a call for papers, with a deadline of TODAY.
Call for Papers
We invite high-quality 2-page extended abstracts in relevant areas, such as:
Simulation Environments
Visual Navigation
Rearrangement
Embodied Question Answering
Simulation-to-Real Transfer
Embodied Vision & Language
Accepted papers will be presented as posters. These papers will be made publicly available in a non-archival format, allowing future submission to archival journals or conferences.
Submission
The submission deadline is May 14th (Anywhere on Earth). Papers should be no longer than 2 pages (excluding references) and styled in the CVPR format. Paper submissions are now open.
I assume anyone submitting to this already has their paper well underway, but this is your reminder to git'r done.
Yeah, so that happened on my attempt to get some rest on my Sabbath day.
I'm not going to cite the book - I'm going to do the author the courtesy of re-reading the relevant passages to make sure I'm not misconstruing them, but I'm not going to wait to blog my reaction - but what caused me to throw this book, an analysis of the flaws of the scientific method, was this bit:
Imagine an experiment with two possible outcomes: the new theory (cough EINSTEIN) and the old one (cough NEWTON). Three instruments are set up. Two report numbers consistent with the new theory; the third one, missing parts, possibly configured improperly and producing noisy data, matches the old.
Wow! News flash: any responsible working scientist would say these results favored the new theory. In fact, if they were really experienced, they might have even thrown out the third instrument entirely - I've learned, based on red herrings from bad readings, that it's better not to look too closely at bad data.
What did the author say, however? Words to the effect: "The scientists ignored the results from the third instrument which disproved their theory and supported the original, and instead, pushing their agenda, wrote a paper claiming that the results of the experiment supported their idea."
Pushing an agenda? Wait, let me get this straight, Chester Chucklewhaite: we should throw out two results from well-functioning instruments that support theory A in favor of one result from an obviously messed-up instrument that support theory B - oh, hell, you're a relativity doubter, aren't you?
Chuck-toss.
I'll go back to this later, after I've read a few more sections of E. T. Jaynes's Probability Theory: The Logic of Science as an antidote.
-the Centaur
P. S. I am not saying relativity is right or wrong, friend. I'm saying the responsible interpretation of those experimental results as described would be precisely the interpretation those scientists put forward - though, in all fairness to the author of this book, the scientist involved appears to have been a super jerk.
Growing up with Superman comics, Hollywood movies and Greek mythology can give you a distorted idea of the spiritual world. Colorful heroes with flashy powers hurl villains into the Phantom Zone, and a plucky bard with a fancy lyres can sing his way into hell to rescue his bride, if only he doesn't look back.
This models the afterlife as a distant but reachable part of the natural world. The word "supernatural" gets tossed around without force, because there are rules for breaking the rules: like warp drive breaking the laws of motion or the cheat codes to the Matrix, you can hack your way into and out of the afterlife.
But spirituality is not magic, and prayers aren't spells. While I've argued "spirit" isn't strictly necessary for the practice of Christianity, most theologians would agree that the supernatural realm is a reflection of the grander reality of God and operates on His will - not a set of rules that could be manipulated by Man.
Even the idea of the "afterlife" isn't necessary. We're waiting in hope for bodily resurrection. We die, and stay dead, yet our essences live on in the mind of God, to be resurrected in a future world which outstrips even our boldest imaginations (though C. S. Lewis sure tried in The Great Divorce and The Last Battle).
Death, in this view, is a one-way trajectory. It isn't likely that people are going to and returning from the afterlife, no matter how many tunnels of light are reported by hypoxia patients, because the afterlife is not a quasi-physical realm to be hacked into, but a future physical state accompanied by spiritual perfection.
So if no-one's come back from Heaven to tell us about the afterlife, how do we know to seek it?
This is not trivial for someone who teaches robots to learn. In reinforcement learning, we model decision making as Markov decision processes, a mathematical formalism in which we choose actions in states to receive rewards, and use the rewards to estimate the values of those actions to make better choices.
But if no-one has returned from a visit to the state of the afterlife, how can we estimate the reward? One typical way around this dilemma is imitation learning: the trajectories of one agent can be used to inform another agent, granting it knowledge of the rewards in states that it cannot visit.
That agent might be human, or another, more skilled robot. You can imagine it as an army of robots with walkie-talkies trying to cross a minefield: as long as they keep radioing back what they've observed, the other robots can use that information to guide their own paths, continuing to improve.
But we're back to the same problem again: there's no radio in the afterlife, no cell service in Heaven.
One-way trajectories like this exist in physics: black holes. Forget the traversable black holes you see in movies from The Black Hole to Star Trek to Interstellar: a real black hole in general relativity is defined as a region of space where trajectories go in, but do not come back out; its boundary is the event horizon.
It's called the event horizon because no events beyond the horizon affect events outside the horizon. Other than the inexorable pull to suck more world-lines in, no information comes back from the black hole: no reward is recorded for the unvisited states of the Markov decision process.
Death appears to be a black hole, literally and figuratively. We die, remain dead, and are often put in a cold dark place in the ground, communicating nothing back to the world of the living, now on a trajectory beyond the event horizon, heading to that undiscovered country of Shakespeare and Star Trek.
In our robot minefield example, that might be a mine with a radio scrambler, cutting off signals before any other robots could be told not to follow that path. But what if there was someone with a radio who was watching that minefield from above, say a rescue helicopter, signaling down the path from above?
In a world where spirituality is a reflection of the grander reality of God, there's no magical hack which can give us the ability to communicate with the afterlife. But in a world where every observed particle event has irreducible randomness, God has plenty of room to turn around and contact us.
Like a faster-than-light radio which only works for the Old Ones, we can receive information from God if and only if He chooses to. The Old Testament records many stories of people hearing the voice of God - in dreams, in waking, in writing on the wall, in voices thundering from the heaven, in whispers.
You don't need to treat the Bible like a fax from God to imagine that the information it contains could be inconceivably precious, a deposit of revelation which could never be received from any amount of human experience. No wonder the Church preserved these books and guarded them so jealously.
But even this sells short the value that we get from God incarnating as Jesus.
Jesus Christ, a human being, provides a direct model of the behavior we should follow, informed by the knowledge of Jesus God, the portion of the Trinity most directly comprehensible by us. This is the best example we could have for imitation learning: a trace of the behavior of a divinely inspired teacher.
No amount of flying around the Earth will bring someone back from the dead; there may very well be "a secret chord that pleases the Lord," but you can't sing yourself into the afterlife. Fortunately, the afterlife has already sent an emissary, showing us the behavior we need to model to follow Him there.
Wow. It's been a long time. Or perhaps not as long as I thought, but I've definitely not been able to post as much as I wanted over the last six months or so. But it's been for good reasons: I've been working on a lot of writing projects. The Dakota Frost / Cinnamon Frost "Hexology", which was a six book series; the moment I finished those rough drafts, it seemed, I rolled into National Novel Writing Month and worked on JEREMIAH WILLSTONE AND THE MACHINERY OF THE APOCALYPSE. Meanwhile, at work, I've been snowed under following up on our PRM-RL paper.
But I've been having fun! The MACHINERY OF THE APOCALYPSE is (at least possibly) spaaaace steampunk, which has led me to learn all sorts of things about space travel and rockets and angular momentum which I somehow didn't learn when I was writing pure hard science fiction. I've learned so much about creating artificial languages as part of the HEXOLOGY.
So, hopefully I will have some time to start sharing this information again, assuming that no disasters befall me in the middle of the night.
So, this happened! Our team's paper on "PRM-RL" - a way to teach robots to navigate their worlds which combines human-designed algorithms that use roadmaps with deep-learned algorithms to control the robot itself - won a best paper award at the ICRA robotics conference!
I talked a little bit about how PRM-RL works in the post "Learning to Drive ... by Learning Where You Can Drive", so I won't go over the whole spiel here - but the basic idea is that we've gotten good at teaching robots to control themselves using a technique called deep reinforcement learning (the RL in PRM-RL) that trains them in simulation, but it's hard to extend this approach to long-range navigation problems in the real world; we overcome this barrier by using a more traditional robotic approach, probabilistic roadmaps (the PRM in PRM-RL), which build maps of where the robot can drive using point to point connections; we combine these maps with the robot simulator and, boom, we have a map of where the robot thinks it can successfully drive.
We were cited not just for this technique, but for testing it extensively in simulation and on two different kinds of robots. I want to thank everyone on the team - especially Sandra Faust for her background in PRMs and for taking point on the idea (and doing all the quadrotor work with Lydia Tapia), for Oscar Ramirez and Marek Fiser for their work on our reinforcement learning framework and simulator, for Kenneth Oslund for his heroic last-minute push to collect the indoor robot navigation data, and to our manager James for his guidance, contributions to the paper and support of our navigation work.
Woohoo! Thanks again everyone!
-the Centaur
When I was a kid (well, a teenager) I'd read puzzle books for pure enjoyment. I'd gotten started with Martin Gardner's mathematical recreation books, but the ones I really liked were Raymond Smullyan's books of logic puzzles. I'd go to Wendy's on my lunch break at Francis Produce, with a little notepad and a book, and chew my way through a few puzzles. I'll admit I often skipped ahead if they got too hard, but I did my best most of the time.
I read more of these as an adult, moving back to the Martin Gardner books. But sometime, about twenty-five years ago (when I was in the thick of grad school) my reading needs completely overwhelmed my reading ability. I'd always carried huge stacks of books home from the library, never finishing all of them, frequently paying late fees, but there was one book in particular - The Emotions by Nico Frijda - which I finished but never followed up on.
Over the intervening years, I did finish books, but read most of them scattershot, picking up what I needed for my creative writing or scientific research. Eventually I started using the tiny little notetabs you see in some books to mark the stuff that I'd written, a "levels of processing" trick to ensure that I was mindfully reading what I wrote.
A few years ago, I admitted that wasn't enough, and consciously began trying to read ahead of what I needed to for work. I chewed through C++ manuals and planning books and was always rewarded a few months later when I'd already read what I needed to to solve my problems. I began focusing on fewer books in depth, finishing more books than I had in years.
Even that wasn't enough, and I began - at last - the re-reading project I'd hoped to do with The Emotions. Recently I did that with Dedekind's Essays on the Theory of Numbers, but now I'm doing it with the Deep Learning. But some of that math is frickin' beyond where I am now, man. Maybe one day I'll get it, but sometimes I've spent weeks tackling a problem I just couldn't get.
Enter puzzles. As it turns out, it's really useful for a scientist to also be a science fiction writer who writes stories about a teenaged mathematical genius! I've had to simulate Cinnamon Frost's staggering intellect for the purpose of writing the Dakota Frost stories, but the further I go, the more I want her to be doing real math. How did I get into math? Puzzles!
So I gave her puzzles. And I decided to return to my old puzzle books, some of the ones I got later but never fully finished, and to give them the deep reading treatment. It's going much slower than I like - I find myself falling victim to the "rule of threes" (you can do a third of what you want to do, often in three times as much time as you expect) - but then I noticed something interesting.
Some of Smullyan's books in particular are thinly disguised math books. In some parts, they're even the same math I have to tackle in my own work. But unlike the other books, these problems are designed to be solved, rather than a reflection of some chunk of reality which may be stubborn; and unlike the other books, these have solutions along with each problem.
So, I've been solving puzzles ... with careful note of how I have been failing to solve puzzles. I've hinted at this before, but understanding how you, personally, usually fail is a powerful technique for debugging your own stuck points. I get sloppy, I drop terms from equations, I misunderstand conditions, I overcomplicate solutions, I grind against problems where I should ask for help, I rabbithole on analytical exploration, and I always underestimate the time it will take for me to make the most basic progress.
Know your weaknesses. Then you can work those weak mental muscles, or work around them to build complementary strengths - the way Richard Feynman would always check over an equation when he was done, looking for those places where he had flipped a sign.
Back to work!
-the Centaur
Pictured: my "stack" at a typical lunch. I'll usually get to one out of three of the things I bring for myself to do. Never can predict which one though.
SO! There I was, trying to solve the mysteries of the universe, learn about deep learning, and teach myself enough puzzle logic to create credible puzzles for the Cinnamon Frost books, and I find myself debugging the fine details of a visualization system I've developed in Mathematica to analyze the distribution of problems in an odd middle chapter of Raymond Smullyan's The Lady or the Tiger.
I meant well! Really I did. I was going to write a post about how finding a solution is just a little bit harder than you normally think, and how insight sometimes comes after letting things sit.
But the tools I was creating didn't do what I wanted, so I went deeper and deeper down the rabbit hole trying to visualize them.
The short answer seems to be that there's no "there" there and that further pursuit of this sub-problem will take me further and further away from the real problem: writing great puzzles!
I learned a lot - about numbers, about how things could combinatorially explode, about Ulam Spirals and how to code them algorithmically. I even learned something about how I, particularly, fail in these cases.
But it didn't provide the insights I wanted. Feynman warned about this: he called it "the computer disease", worrying about the formatting of the printout so much you forget about the answer you're trying to produce, and it can strike anyone in my line of work.
Back to that work.
-the Centaur
I often say "I teach robots to learn," but what does that mean, exactly? Well, now that one of the projects that I've worked on has been announced - and I mean, not just on arXiv, the public access scientific repository where all the hottest reinforcement learning papers are shared, but actually, accepted into the ICRA 2018 conference - I can tell you all about it!
When I'm not roaming the corridors hammering infrastructure bugs, I'm trying to teach robots to roam those corridors - a problem we call robot navigation. Our team's latest idea combines "traditional planning," where the robot tries to navigate based on an explicit model of its surroundings, with "reinforcement learning," where the robot learns from feedback on its performance.
For those not in the know, "traditional" robotic planners use structures like graphs to plan routes, much in the same way that a GPS uses a roadmap. One of the more popular methods for long-range planning are probabilistic roadmaps, which build a long-range graph by picking random points and attempting to connect them by a simpler "local planner" that knows how to navigate shorter distances. It's a little like how you learn to drive in your neighborhood - starting from landmarks you know, you navigate to nearby points, gradually building up a map in your head of what connects to what.
But for that to work, you have to know how to drive, and that's where the local planner comes in. Building a local planner is simple in theory - you can write one for a toy world in a few dozen lines of code - but difficult in practice, and making one that works on a real robot is quite the challenge. These software systems are called "navigation stacks" and can contain dozens of components - and in my experience they're hard to get working and even when you do, they're often brittle, requiring many engineer-months to transfer to new domains or even just to new buildings.
People are much more flexible, learning from their mistakes, and the science of making robots learn from their mistakes is reinforcement learning, in which an agent learns a policy for choosing actions by simply trying them, favoring actions that lead to success and suppressing ones that lead to failure. Our team built a deep reinforcement learning approach to local planning, using a state-of-the art algorithm called DDPG (Deep Deterministic Policy Gradients) pioneered by DeepMind to learn a navigation system that could successfully travel several meters in office-like environments.
But there's a further wrinkle: the so-called "reality gap". By necessity, the local planner used by a probablistic roadmap is simulated - attempting to connect points on a map. That simulated local planner isn't identical to the real-world navigation stack running on the robot, so sometimes the robot thinks it can go somewhere on a map which it can't navigate safely in the real world. This can have disastrous consequences - causing robots to tumble down stairs, or, worse, when people follow their GPSes too closely without looking where they're going, causing cars to tumble off the end of a bridge.
Our approach, PRM-RL, directly combats the reality gap by combining probabilistic roadmaps with deep reinforcement learning. By necessity, reinforcement learning navigation systems are trained in simulation and tested in the real world. PRM-RL uses a deep reinforcement learning system as both the probabilistic roadmap's local planner and the robot's navigation system. Because links are added to the roadmap only if the reinforcement learning local controller can traverse them, the agent has a better chance of attempting to execute its plans in the real world.
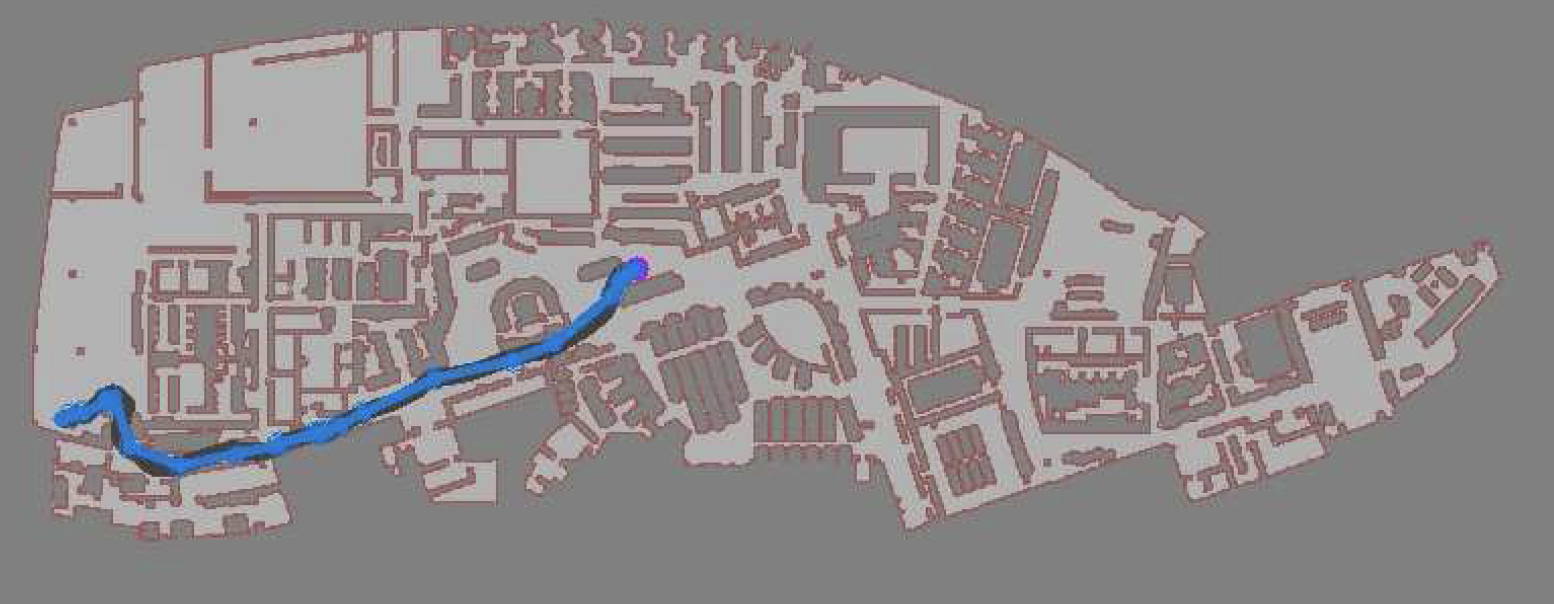
In simulation, our agent could traverse hundreds of meters using the PRM-RL approach, doing much better than a "straight-line" local planner which was our default alternative. While I didn't happen to have in my back pocket a hundred-meter-wide building instrumented with a mocap rig for our experiments, we were able to test a real robot on a smaller rig and showed that it worked well (no pictures, but you can see the map and the actual trajectories below; while the robot's behavior wasn't as good as we hoped, we debugged that to a networking issue that was adding a delay to commands sent to the robot, and not in our code itself; we'll fix this in a subsequent round).
This work includes both our group working on office robot navigation - including Alexandra Faust, Oscar Ramirez, Marek Fiser, Kenneth Oslund, me, and James Davidson - and Alexandra's collaborator Lydia Tapia, with whom she worked on the aerial navigation also reported in the paper. Until the ICRA version comes out, you can find the preliminary version on arXiv:
https://arxiv.org/abs/1710.03937
PRM-RL: Long-range Robotic Navigation Tasks by Combining Reinforcement Learning and Sampling-based Planning
We present PRM-RL, a hierarchical method for long-range navigation task completion that combines sampling-based path planning with reinforcement learning (RL) agents. The RL agents learn short-range, point-to-point navigation policies that capture robot dynamics and task constraints without knowledge of the large-scale topology, while the sampling-based planners provide an approximate map of the space of possible configurations of the robot from which collision-free trajectories feasible for the RL agents can be identified. The same RL agents are used to control the robot under the direction of the planning, enabling long-range navigation. We use the Probabilistic Roadmaps (PRMs) for the sampling-based planner. The RL agents are constructed using feature-based and deep neural net policies in continuous state and action spaces. We evaluate PRM-RL on two navigation tasks with non-trivial robot dynamics: end-to-end differential drive indoor navigation in office environments, and aerial cargo delivery in urban environments with load displacement constraints. These evaluations included both simulated environments and on-robot tests. Our results show improvement in navigation task completion over both RL agents on their own and traditional sampling-based planners. In the indoor navigation task, PRM-RL successfully completes up to 215 meters long trajectories under noisy sensor conditions, and the aerial cargo delivery completes flights over 1000 meters without violating the task constraints in an environment 63 million times larger than used in training.
So, when I say "I teach robots to learn" ... that's what I do.
-the Centaur
What makes you hang on the edge of your seat? I call that a favorite, and I talk about some of my current faves over at the Speculative Chic blog!
[embed]http://speculativechic.com/2017/12/18/my-favorite-things-with-anthony-francis/[/embed]
Go check it out!
Simply put, "artificial intelligence” is people trying to make things do things that we’d call smart if done by people.
So what’s the big deal about that?
Well, as it turns out, a lot of people get quite wound up with the definition of "artificial intelligence.” Sometimes this is because they’re invested in a prescientific notion that machines can’t be intelligent and want to define it in a way that writes the field off before it gets started, or it’s because they’re invested in an unscientific degree into their particular theory of intelligence and want to define it in a way that constrains the field to look at only the things they care about, or because they’re actually not scientific at all and want to proscribe the field to work on the practical problems of particular interest to them.
No, I’m not bitter about having to wade through a dozen bad definitions of artificial intelligence as part of a survey. Why do you ask?
Wishful thinking won't land a man on the moon, but it might get us all killed - fortunately, though, we have people who know how to nail a good landing.
All we have to do now is preserve the fruits of their labors.
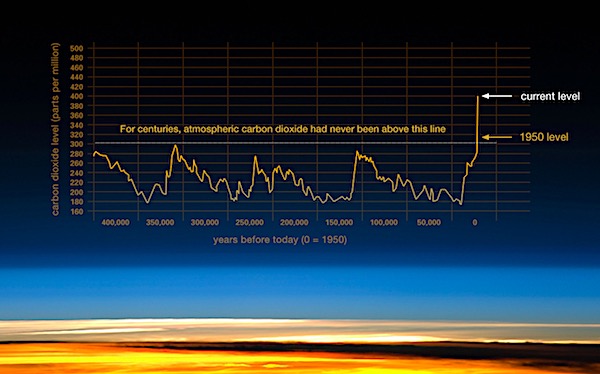
Now that a climate denier is barreling towards the presidency, other climate deniers are coming out of the woodwork, but fortunately, NASA has a great site telling the story of climate change. For those who haven’t been keeping score at home, the too-simple story is that humans have pumped vast amounts of carbon dioxide in the atmosphere in the past few decades, amounts that in the geological record resulted in disastrous temperature changes - and it’s really convenient for a lot of people to deny that.
Now, I said it’s a too-simple story, and there are a lot of good references on climate change, like Henson’s The Rough Guide to Climate Change. But, technically, that could be considered a polemic, and if you want to really dig deep, you need to go for a textbook instead, one presenting a broad overview of the science without pushing an agenda. For example, Understanding Weather and Climate has a great chapter (Chapter 16 in the 4th edition) that breaks down some of the science behind global climate change (human and not) and why anthropogenic climate change is both very tricky to study - and still very worrisome.
And because I am a scientist, and I am not afraid to consider warranted arguments on both sides of any scientific question, I also want to call out Human Impacts on Weather and Climate 2/e by Cotton and Pielke, which in Chapter 8 and the Epilogue take a more skeptical view of our predictive power. In their view, well-argued in my opinion, current climate models are sensitivity studies, not forecasts; they merely establish the vulnerability of our systems to forcing factors like excess carbon, and don’t take into account areas of natural variability which might seriously alter the outcomes. And, yes, they are worried about climate groupthink.
Yes, they’re climate skeptics. But no-one is burning them at the stake. No-one is shunning them at conferences. People like me who believe in climate change read their papers with interest (especially Pielke’s work, which while it in some ways makes CO2 less of an issue and in some ways makes other human impacts seem worse). Still, Cotton and Pielke think the right approach is “sustained, stable national funding at a high level” and decry the politicization of science in either direction.
Do you see why people who study climate change in enough depth to see where the science is really not settled end up walking away more unsettled about the future of our planet, not less? And why we stand up and say NO when someone else comes forward saying the “science is not settled” while acting like the science has already been settled in their favor?
"Have fun warming the planet!” Just hope it doesn’t inundateFlorida. I’d love to tell you that the projected 1M sea rise discussed in the Florida resource isn’t as bad as the Geology.com map’s default 6m projections, but unfortunately, sea level seems to be rising in Florida faster than the IPCC projections, and if the science isn’t really settled, we could have a sea level rise of … jeez. After reviewing some of the research I don’t even want to tell you. The “good” news is, hey, the seas might fall too.









 Yeah, so that happened on my attempt to get some rest on my Sabbath day.
I'm not going to cite the book - I'm going to do the author the courtesy of re-reading the relevant passages to make sure I'm not misconstruing them, but I'm not going to wait to blog my reaction - but what caused me to throw this book, an analysis of the flaws of the scientific method, was this bit:
Imagine an experiment with two possible outcomes: the new theory (cough EINSTEIN) and the old one (cough NEWTON). Three instruments are set up. Two report numbers consistent with the new theory; the third one, missing parts, possibly configured improperly and producing noisy data, matches the old.
Wow! News flash: any responsible working scientist would say these results favored the new theory. In fact, if they were really experienced, they might have even thrown out the third instrument entirely - I've learned, based on red herrings from bad readings, that it's better not to look too closely at bad data.
What did the author say, however? Words to the effect: "The scientists ignored the results from the third instrument which disproved their theory and supported the original, and instead, pushing their agenda, wrote a paper claiming that the results of the experiment supported their idea."
Pushing an agenda? Wait, let me get this straight, Chester Chucklewhaite: we should throw out two results from well-functioning instruments that support theory A in favor of one result from an obviously messed-up instrument that support theory B - oh, hell, you're a relativity doubter, aren't you?
Chuck-toss.
I'll go back to this later, after I've read a few more sections of E. T. Jaynes's Probability Theory: The Logic of Science as an antidote.
-the Centaur
P. S. I am not saying relativity is right or wrong, friend. I'm saying the responsible interpretation of those experimental results as described would be precisely the interpretation those scientists put forward - though, in all fairness to the author of this book, the scientist involved appears to have been a super jerk.
Yeah, so that happened on my attempt to get some rest on my Sabbath day.
I'm not going to cite the book - I'm going to do the author the courtesy of re-reading the relevant passages to make sure I'm not misconstruing them, but I'm not going to wait to blog my reaction - but what caused me to throw this book, an analysis of the flaws of the scientific method, was this bit:
Imagine an experiment with two possible outcomes: the new theory (cough EINSTEIN) and the old one (cough NEWTON). Three instruments are set up. Two report numbers consistent with the new theory; the third one, missing parts, possibly configured improperly and producing noisy data, matches the old.
Wow! News flash: any responsible working scientist would say these results favored the new theory. In fact, if they were really experienced, they might have even thrown out the third instrument entirely - I've learned, based on red herrings from bad readings, that it's better not to look too closely at bad data.
What did the author say, however? Words to the effect: "The scientists ignored the results from the third instrument which disproved their theory and supported the original, and instead, pushing their agenda, wrote a paper claiming that the results of the experiment supported their idea."
Pushing an agenda? Wait, let me get this straight, Chester Chucklewhaite: we should throw out two results from well-functioning instruments that support theory A in favor of one result from an obviously messed-up instrument that support theory B - oh, hell, you're a relativity doubter, aren't you?
Chuck-toss.
I'll go back to this later, after I've read a few more sections of E. T. Jaynes's Probability Theory: The Logic of Science as an antidote.
-the Centaur
P. S. I am not saying relativity is right or wrong, friend. I'm saying the responsible interpretation of those experimental results as described would be precisely the interpretation those scientists put forward - though, in all fairness to the author of this book, the scientist involved appears to have been a super jerk.


 So, this happened! Our team's paper on "PRM-RL" - a way to teach robots to navigate their worlds which combines human-designed algorithms that use roadmaps with deep-learned algorithms to control the robot itself - won a best paper award at the ICRA robotics conference!
So, this happened! Our team's paper on "PRM-RL" - a way to teach robots to navigate their worlds which combines human-designed algorithms that use roadmaps with deep-learned algorithms to control the robot itself - won a best paper award at the ICRA robotics conference!
 I talked a little bit about how PRM-RL works in the post "
I talked a little bit about how PRM-RL works in the post " We were cited not just for this technique, but for testing it extensively in simulation and on two different kinds of robots. I want to thank everyone on the team - especially Sandra Faust for her background in PRMs and for taking point on the idea (and doing all the quadrotor work with Lydia Tapia), for Oscar Ramirez and Marek Fiser for their work on our reinforcement learning framework and simulator, for Kenneth Oslund for his heroic last-minute push to collect the indoor robot navigation data, and to our manager James for his guidance, contributions to the paper and support of our navigation work.
We were cited not just for this technique, but for testing it extensively in simulation and on two different kinds of robots. I want to thank everyone on the team - especially Sandra Faust for her background in PRMs and for taking point on the idea (and doing all the quadrotor work with Lydia Tapia), for Oscar Ramirez and Marek Fiser for their work on our reinforcement learning framework and simulator, for Kenneth Oslund for his heroic last-minute push to collect the indoor robot navigation data, and to our manager James for his guidance, contributions to the paper and support of our navigation work.
 Woohoo! Thanks again everyone!
-the Centaur
Woohoo! Thanks again everyone!
-the Centaur  When I was a kid (well, a teenager) I'd read puzzle books for pure enjoyment. I'd gotten started with Martin Gardner's mathematical recreation books, but the ones I really liked were Raymond Smullyan's books of logic puzzles. I'd go to Wendy's on my lunch break at Francis Produce, with a little notepad and a book, and chew my way through a few puzzles. I'll admit I often skipped ahead if they got too hard, but I did my best most of the time.
I read more of these as an adult, moving back to the Martin Gardner books. But sometime, about twenty-five years ago (when I was in the thick of grad school) my reading needs completely overwhelmed my reading ability. I'd always carried huge stacks of books home from the library, never finishing all of them, frequently paying late fees, but there was one book in particular - The Emotions by Nico Frijda - which I finished but never followed up on.
Over the intervening years, I did finish books, but read most of them scattershot, picking up what I needed for my creative writing or scientific research. Eventually I started using the tiny little notetabs you see in some books to mark the stuff that I'd written, a "levels of processing" trick to ensure that I was mindfully reading what I wrote.
A few years ago, I admitted that wasn't enough, and consciously began trying to read ahead of what I needed to for work. I chewed through C++ manuals and planning books and was always rewarded a few months later when I'd already read what I needed to to solve my problems. I began focusing on fewer books in depth, finishing more books than I had in years.
Even that wasn't enough, and I began - at last - the re-reading project I'd hoped to do with The Emotions. Recently I did that with Dedekind's Essays on the Theory of Numbers, but now I'm doing it with the Deep Learning. But some of that math is frickin' beyond where I am now, man. Maybe one day I'll get it, but sometimes I've spent weeks tackling a problem I just couldn't get.
Enter puzzles. As it turns out, it's really useful for a scientist to also be a science fiction writer who writes stories about a teenaged mathematical genius! I've had to simulate Cinnamon Frost's staggering intellect for the purpose of writing the Dakota Frost stories, but the further I go, the more I want her to be doing real math. How did I get into math? Puzzles!
So I gave her puzzles. And I decided to return to my old puzzle books, some of the ones I got later but never fully finished, and to give them the deep reading treatment. It's going much slower than I like - I find myself falling victim to the "rule of threes" (you can do a third of what you want to do, often in three times as much time as you expect) - but then I noticed something interesting.
Some of Smullyan's books in particular are thinly disguised math books. In some parts, they're even the same math I have to tackle in my own work. But unlike the other books, these problems are designed to be solved, rather than a reflection of some chunk of reality which may be stubborn; and unlike the other books, these have solutions along with each problem.
So, I've been solving puzzles ... with careful note of how I have been failing to solve puzzles. I've hinted at this before, but understanding how you, personally, usually fail is a powerful technique for debugging your own stuck points. I get sloppy, I drop terms from equations, I misunderstand conditions, I overcomplicate solutions, I grind against problems where I should ask for help, I rabbithole on analytical exploration, and I always underestimate the time it will take for me to make the most basic progress.
Know your weaknesses. Then you can work those weak mental muscles, or work around them to build complementary strengths - the way Richard Feynman would always check over an equation when he was done, looking for those places where he had flipped a sign.
Back to work!
-the Centaur
Pictured: my "stack" at a typical lunch. I'll usually get to one out of three of the things I bring for myself to do. Never can predict which one though.
When I was a kid (well, a teenager) I'd read puzzle books for pure enjoyment. I'd gotten started with Martin Gardner's mathematical recreation books, but the ones I really liked were Raymond Smullyan's books of logic puzzles. I'd go to Wendy's on my lunch break at Francis Produce, with a little notepad and a book, and chew my way through a few puzzles. I'll admit I often skipped ahead if they got too hard, but I did my best most of the time.
I read more of these as an adult, moving back to the Martin Gardner books. But sometime, about twenty-five years ago (when I was in the thick of grad school) my reading needs completely overwhelmed my reading ability. I'd always carried huge stacks of books home from the library, never finishing all of them, frequently paying late fees, but there was one book in particular - The Emotions by Nico Frijda - which I finished but never followed up on.
Over the intervening years, I did finish books, but read most of them scattershot, picking up what I needed for my creative writing or scientific research. Eventually I started using the tiny little notetabs you see in some books to mark the stuff that I'd written, a "levels of processing" trick to ensure that I was mindfully reading what I wrote.
A few years ago, I admitted that wasn't enough, and consciously began trying to read ahead of what I needed to for work. I chewed through C++ manuals and planning books and was always rewarded a few months later when I'd already read what I needed to to solve my problems. I began focusing on fewer books in depth, finishing more books than I had in years.
Even that wasn't enough, and I began - at last - the re-reading project I'd hoped to do with The Emotions. Recently I did that with Dedekind's Essays on the Theory of Numbers, but now I'm doing it with the Deep Learning. But some of that math is frickin' beyond where I am now, man. Maybe one day I'll get it, but sometimes I've spent weeks tackling a problem I just couldn't get.
Enter puzzles. As it turns out, it's really useful for a scientist to also be a science fiction writer who writes stories about a teenaged mathematical genius! I've had to simulate Cinnamon Frost's staggering intellect for the purpose of writing the Dakota Frost stories, but the further I go, the more I want her to be doing real math. How did I get into math? Puzzles!
So I gave her puzzles. And I decided to return to my old puzzle books, some of the ones I got later but never fully finished, and to give them the deep reading treatment. It's going much slower than I like - I find myself falling victim to the "rule of threes" (you can do a third of what you want to do, often in three times as much time as you expect) - but then I noticed something interesting.
Some of Smullyan's books in particular are thinly disguised math books. In some parts, they're even the same math I have to tackle in my own work. But unlike the other books, these problems are designed to be solved, rather than a reflection of some chunk of reality which may be stubborn; and unlike the other books, these have solutions along with each problem.
So, I've been solving puzzles ... with careful note of how I have been failing to solve puzzles. I've hinted at this before, but understanding how you, personally, usually fail is a powerful technique for debugging your own stuck points. I get sloppy, I drop terms from equations, I misunderstand conditions, I overcomplicate solutions, I grind against problems where I should ask for help, I rabbithole on analytical exploration, and I always underestimate the time it will take for me to make the most basic progress.
Know your weaknesses. Then you can work those weak mental muscles, or work around them to build complementary strengths - the way Richard Feynman would always check over an equation when he was done, looking for those places where he had flipped a sign.
Back to work!
-the Centaur
Pictured: my "stack" at a typical lunch. I'll usually get to one out of three of the things I bring for myself to do. Never can predict which one though. 
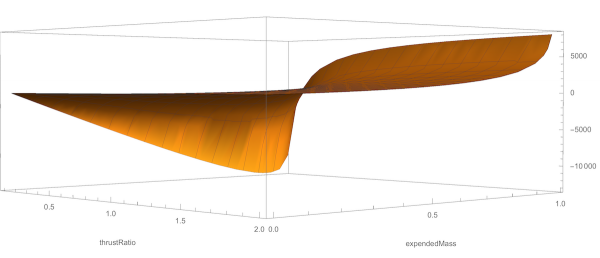
 SO! There I was, trying to solve the mysteries of the universe, learn about deep learning, and teach myself enough puzzle logic to create credible puzzles for the Cinnamon Frost books, and I find myself debugging the fine details of a visualization system I've developed in Mathematica to analyze the distribution of problems in an odd middle chapter of Raymond Smullyan's
SO! There I was, trying to solve the mysteries of the universe, learn about deep learning, and teach myself enough puzzle logic to create credible puzzles for the Cinnamon Frost books, and I find myself debugging the fine details of a visualization system I've developed in Mathematica to analyze the distribution of problems in an odd middle chapter of Raymond Smullyan's  I meant well! Really I did. I was going to write a post about how finding a solution is just a little bit harder than you normally think, and how insight sometimes comes after letting things sit.
I meant well! Really I did. I was going to write a post about how finding a solution is just a little bit harder than you normally think, and how insight sometimes comes after letting things sit.
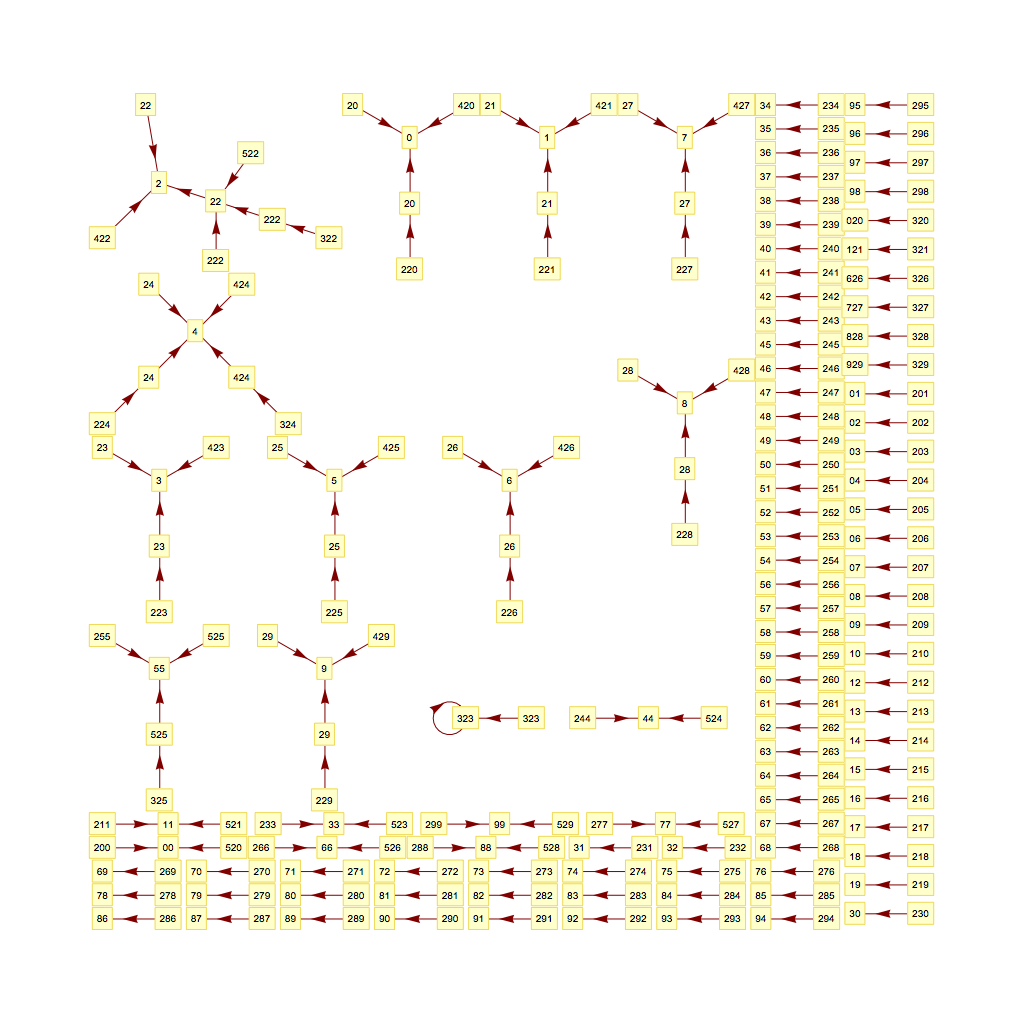 But the tools I was creating didn't do what I wanted, so I went deeper and deeper down the rabbit hole trying to visualize them.
But the tools I was creating didn't do what I wanted, so I went deeper and deeper down the rabbit hole trying to visualize them.
 The short answer seems to be that there's no "there" there and that further pursuit of this sub-problem will take me further and further away from the real problem: writing great puzzles!
The short answer seems to be that there's no "there" there and that further pursuit of this sub-problem will take me further and further away from the real problem: writing great puzzles!
 I learned a lot - about numbers, about how things could combinatorially explode, about
I learned a lot - about numbers, about how things could combinatorially explode, about 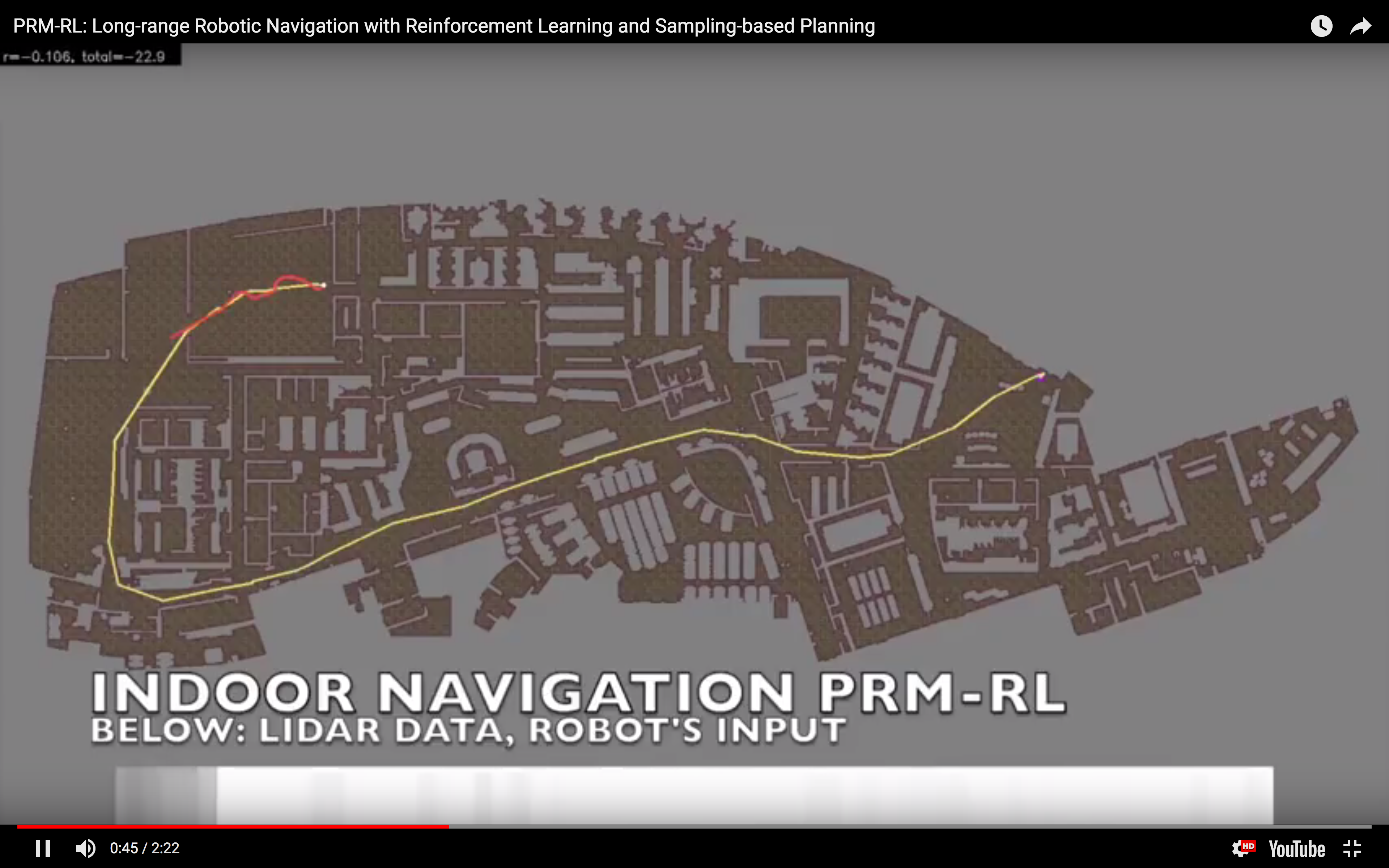 I often say "I teach robots to learn," but what does that mean, exactly? Well, now that one of the projects that I've worked on has been announced - and I mean, not just on
I often say "I teach robots to learn," but what does that mean, exactly? Well, now that one of the projects that I've worked on has been announced - and I mean, not just on 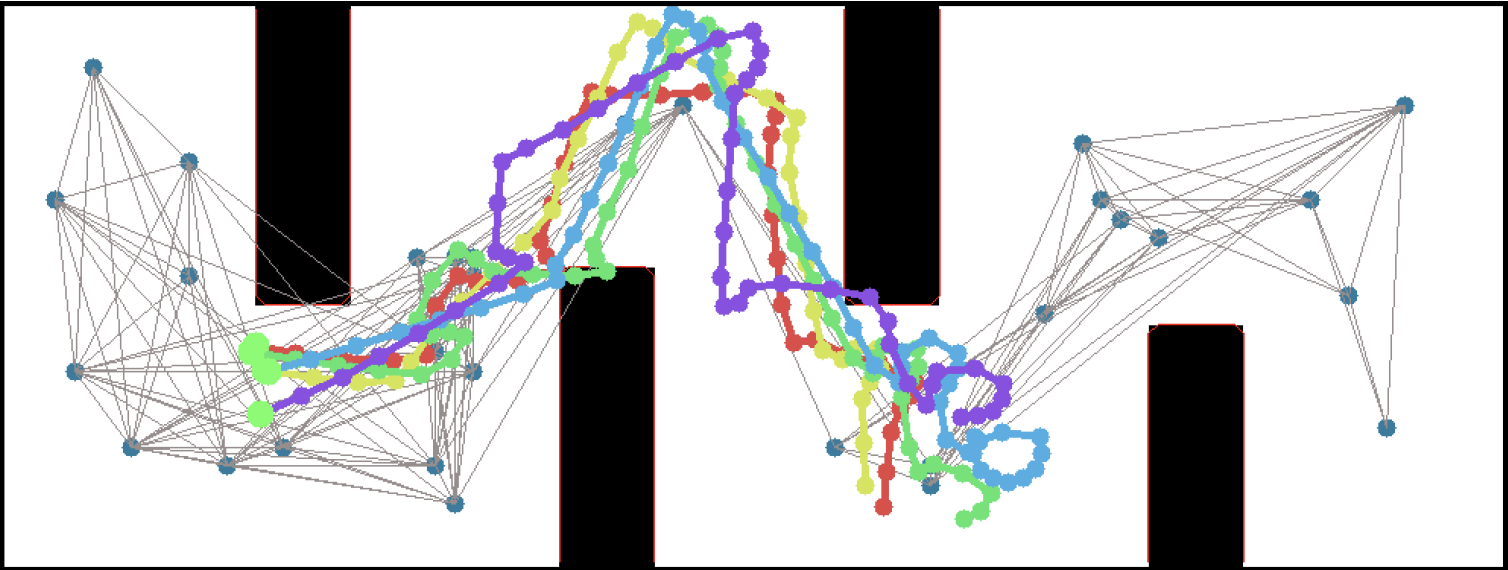 This work includes both our group working on office robot navigation - including Alexandra Faust, Oscar Ramirez, Marek Fiser, Kenneth Oslund, me, and James Davidson - and Alexandra's collaborator Lydia Tapia, with whom she worked on the aerial navigation also reported in the paper. Until the ICRA version comes out, you can find the preliminary version on arXiv:
This work includes both our group working on office robot navigation - including Alexandra Faust, Oscar Ramirez, Marek Fiser, Kenneth Oslund, me, and James Davidson - and Alexandra's collaborator Lydia Tapia, with whom she worked on the aerial navigation also reported in the paper. Until the ICRA version comes out, you can find the preliminary version on arXiv: