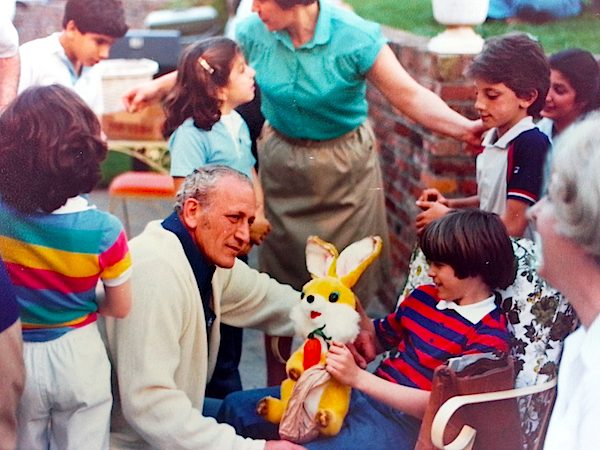
He is risen. Let us rejoice and be glad in this. Take this time to find your families and renew your bonds of love.
-the Centaur
Pictured: me, Dad, and blurry at the edge of the picture, Mom … all a long time ago.
Words, Art & Science by Anthony Francis
He is risen. Let us rejoice and be glad in this. Take this time to find your families and renew your bonds of love.
-the Centaur
Pictured: me, Dad, and blurry at the edge of the picture, Mom … all a long time ago.

Once again it’s time for GDC, the Game Developers Conference. This annual kickstart to my computational creativity is held in the Moscone Center in San Francisco, CA and attracts roughly twenty thousand developers from all over the world.
I’m interested primarily in artificial intelligence for computer games– “Game AI” – and in the past few years they’ve had an AI Summit where game AI programmers can get together to hear neat talks about progress in the field.
Coming from an Academic AI background, what I like about Game AI is that it can’t not work. The AI for a game must work, come hell or high water. It doesn’t need to be principled. It doesn’t need to be real. It can be a random number generator. But it needs to appear to work—it has to affect gameplay, and users have to notice it.

That having been said, there are an enormous number of things getting standard in game artificial intelligence – agents and their properties, actions and decision algorithms, pathfinding and visibility, multiple agent interactions, animation and intent communication, and so forth – and they’re getting better all the time.
I know this is what I’m interested in, so I go to the AI Summit on Monday and Tuesday, some subset of the AI Roundtables, other programming, animation, and tooling talks, and if I can make it, the AI Programmer’s Dinner on Friday night. But if game AI isn’t your bag, what should you do? What should you see?

If you haven’t been before, GDC can be overwhelming. Obviously, try to go to talks that you like, but how do you navigate this enormous complex in downtown San Francisco? I’ve blogged about this before, but it’s worth a refresher. Here are a few tips that I’ve found improve my experience.
Get your stuff done before you arrive. There is a LOT to see at GDC, and every year it seems that a last minute videoconference bleeds over into some talk that I want to see, or some programming task bumps the timeslot I set aside for a blogpost, or a writing task that does the same. Try to get this stuff done before you arrive.
Build a schedule before the conference. You’ll change your mind the day of, but GDC has a great schedule builder that lets you quickly and easily find candidate talks. Use it, email yourself a copy, print one out, save a PDF, whatever. It will help you know where you need to go.
Get a nearby hotel. The 5th and Minna Garage near GDC is very convenient, but driving there, even just in the City, is a pain. GDC hotels are done several months in advance, but if you hunt on Expedia or your favorite aggregator you might find something. Read the reviews carefully and doublecheck with Yelp so you don’t get bedbugs or mugged.
Check in the day before. Stuff starts really early, so if you want to get to early talks, don’t even bother to fly in the same day. I know this seems obvious, but this isn’t a conference that starts at 5pm on the first day with a reception. The first content-filled talks start at 10am on Monday. Challenge mode: you can check in Sunday if you arrive early enough.

Leave early, find breakfast. Some people don’t care about food, and there’s snacks onsite. Grab a crossaint and cola, or banana and coffee, or whatever. But if you power-up via a good hot breakfast, there are a number of great places to eat nearby – the splendiferous Mo’z Café and the greasy spoon Mel’s leap to mind, but hey, Yelp. A sea of GDC people will be there, and you’ll have the opportunity to network, peoplewatch, and go through your schedule again, even if you don’t find someone to strike up a conversation with.
Ask people who’ve been before what they recommend. This post got started when I left early, got breakfast at Mo’z, and then let some random dude sit down on the table opposite me because the place was too crowded. He didn’t want to disturb my reading, but we talked anyway, and he admitted: “I’ve never been before? What do I do?” Well, I gave him some advice … and then packaged it up into this blogpost. (And this one.)
Network, network, network. Bring business cards. (I am so bad at this!) Take business cards. Introduce yourself to people (but don’t be pushy). Ask what they’re up to. Even if you are looking for a job, you’re not looking for a job: you want people to get to know you first before you stick your hand out. Even if you’re not really looking for a job, you are really looking for a job, three, five or ten years later. I got hired into the Search Engine that Starts with a G from GDC … and I wasn’t even looking.
Learn, learn, learn. Find talks that look like they may answer questions related to problems that you have in your job. Find talks that look directly related to your job. Find talks that look vaguely related to your job. Comb the Expo floor looking for booths that have information even remotely related to your job. Scour the GDC Bookstore for books on anything interesting – but while you’re here: learn, learn, learn.

Leave early if you want lunch or dinner. If you don’t care about a quiet lunch, or you’ve got a group of friends you want to hang with, or colleagues you need to meet with, or have found some people you want to talk to, go with the flow, and feel comfortable using your 30 minute wait to network. But if you’re a harried, slightly antisocial writer with not enough hours in the day needing to work on his or her writing projects aaa aaa they’re chasing me, then leave about 10 minutes before the lunch or dinner rush to find dinner. Nearby places just off the beaten path like the enormous Chevy’s or the slightly farther ’wichcraft are your friends.
Find groups or parties or events to go to. I usually have an already booked schedule, but there are many evening parties. Roundtables break up with people heading to lunch or dinner. There may be guilds or groups or clubs or societies relating to your particular area; find them, and find out where they meet or dine or party or booze. And then network.

Hit Roundtables in person; hit the GDC Vault for conflicts. There are too many talks to go. Really. You’ll have to make sacrifices. Postmortems on classic games are great talks to go to, but pro tip: the GDC Roundtables, where seasoned pros jam with novices trying to answer their questions, are not generally recorded. All other talks usually end up on the GDC Vault, a collection of online recordings of all past sessions, which is expensive unless you…
Get an All Access Pass. Yes, it is expensive. Maybe your company will pay for it; maybe it won’t. But if you really are interested in game development, it’s totally worth it. Bonus: if you come back from year to year, you can get an Alumni discount if you order early. Double bonus: it comes with a GDC Vault subscription.

Don’t Commit to Every Talk. There are too many talks to go to. Really. You’ll have to make sacrifices. Make sure you hit the Expo floor. Make sure you meet with friends. Make sure you make an effort to find some friends. Make time to see some of San Francisco. Don’t wear yourself out: go to as much as you can, then soak the rest of it in. Give yourself a breather. Give yourself an extra ten minutes between talks. Heck, leave a talk if you have to if it isn’t panning out, and find a more interesting one.
Get out of your comfort zone. If you’re a programmer, go to a design talk. If you’re a designer, go to a programming talk. Both of you could probably benefit from sitting in on an audio or animation talk, or to get more details about production. What did I say about learn, learn, learn?
Most importantly, have fun. Games are about fun. Producing them can be hard work, but GDC should not feel like work. It should feel like a grand adventure, where you explore parts of the game development experience you haven’t before, an experience of discovery where you recharge your batteries, reconnect with your field, and return home eager to start coding games once again.
-the Centaur
Pictured: The GDC North Hall staircase, with the mammoth holographic projected GDC logo hovering over it. Note: there is no mammoth holographic projected logo. After that, breakfast at Mo'z, the Expo floor, the Roundtables, and lunch at Chevy's.

I’ve seen many presentations that work: presentations with a few slides, with many slides, with no slides. Presentations with text-heavy slides, with image-heavy slides, with a few bullet points, even hand scrawled. Presentations done almost entirely by a sequence of demos; presentations given off the cuff sans microphone.
But there are a lot of things that don’t work in presentations, and I think it comes down to one root problem: presenters don’t realize they are not their audience. You should know, as a presenter, that you aren’t your audience: you’re presenting, they’re listening, you know what you’re going to say, they don’t.
But recently, I’ve had evidence otherwise. Presenters that seem to think you know what they’re thinking. Presenters that seem to think you have access to their slides. Presenters that seem that you are in on every private joke that they tell. Presenters that not only seem to think that they are standing on the podium with them, but are like them in every way – and like them as well.
Look, let’s be honest. Everyone is unique, and as a presenter, you’re more unique than everyone else. [u*nique |yo͞oˈnēk| adj, def (2): distinctive, remarkable, special, or unusual: a person unique enough to give him a microphone for forty-five minutes]. So your audience is not like you — or they wouldn’t have given you a podium. The room before that podium is filled with people all different from you.
How are they different?
First off, they don’t have your slides. Fine, you can show them to them. But they haven’t read your slides. They don’t know what’s on your slides. They can’t read them as fast as you can flip through them. Heck, you can’t read them as fast as you can flip through them. You have to give them the audience time to read your slides.
Look, I don’t want to throw a lot of rules at you. I know some people say “no more than 3 bullets per slide, no more than 1 slide per 2 minutes” but I’ve seen Scott McCloud give a talk with maybe triple that density, and his daughter Sky McCloud is even faster and better. There are no rules. Just use common sense.
Ok. That’s off my chest.
Now to dive back into the fray…
-the Centaur
Pictured: A slide from ... axually a pretty good talk at GDC, not one of the ones that prompted the letter above.
As I mentioned in a previous post, Google Reader is going away. If you don't use RSS feeds, this service may be mystifying to you, but think of it this way: imagine, instead of getting a bunch of Facebook, Google+ or Twitter randomized micro-posts, you could get a steady stream of high-quality articles just from the people you like and admire? Yeah. RSS. It's like that.
So anyway, the Reader shutdown. I have a lot of thoughts about that, as do many other people, but the first one is: what the heck do I do? I use Reader on average about seven times a day. I'm certainly not going to hope Google change their minds, and even if they do, my trust is gone. Fortunately, there are a number of alternatives, which people have blogged about here and here.
The one I want to report on today is The Old Reader, the first one I tried. AWESOME. In more detail, this is what I found:
There are drawbacks, most notably: they don't yet have an equivalent for Google Takeout's OPML export. But, they are only three guys. They just started taking money, which is a good sign that they might stay around. Here's hoping they are able to build a business on this, and that they have the same commitment to openness that Google had.
I plan to try other feed readers, as I can't be trapped into one product as I was before, but kudos to The Old Reader team for quickly and painlessly rescuing me from the First Great Internet Apocalypse of 2013. I feel like I'm just using Reader, except now I have a warm fuzzy that my beloved service isn't going to get neglected until it withers away.
-the Centaur
 Let me completely up front about my motivation for writing this post: recently, I came across a paper which was similar to the work in my PhD thesis, but applied to a different area. The paper didn’t cite my work – in fact, its survey of related work in the area seemed to indicate that no prior work along the lines of mine existed – and when I alerted the authors to the omission, they informed me they’d cited all relevant work, and claimed “my obscure dissertation probably wasn’t relevant.” Clearly, I haven’t done a good enough job articulating or promoting my work, so I thought I should take a moment to explain what I did for my doctoral dissertation.
My research improved computer memory by modeling it after human memory. People remember different things in different contexts based on how different pieces of information are connected to one another. Even a word as simple as ‘ford’ can call different things to mind depending on whether you’ve bought a popular brand of car, watched the credits of an Indiana Jones movie, or tried to cross the shallow part of a river. Based on that human phenomenon, I built a memory retrieval engine that used context to remember relevant things more quickly.
My approach was based on a technique I called context directed spreading activation, which I argued was an advance over so-called “traditional” spreading activation. Spreading activation is a technique for finding information in a kind of computer memory called semantic networks, which model relationships in the human mind. A semantic network represents knowledge as a graph, with concepts as nodes and relationships between concepts as links, and traditional spreading activation finds information in that network by starting with a set of “query” nodes and propagating “activation” out on the links, like current in an electric circuit. The current that hits each node in the network determines how highly ranked the node is for a query. (If you understand circuits and spreading activation, and this description caused you to catch on fire, my apologies. I’ll be more precise in future blogposts. Roll with it).
The problem is, as semantic networks grow large, there’s a heck of a lot of activation to propagate. My approach, context directed spreading activation (CDSA), cuts this cost dramatically by making activation propagate over fewer types of links. In CDSA, each link has a type, each type has a node, and activation propagates only over links whose nodes are active (to a very rough first approximation, although in my evaluations I tested about every variant of this under the sun). Propagating over active links isn’t just cheaper than spreading activation over every link; it’s smarter: the same “query” nodes can activate different parts of the network, depending on which “context” nodes are active. So, if you design your network right, Harrison Ford is never going to occur to you if you’ve been thinking about cars.
I was a typical graduate student, and I thought my approach was so good, it was good for everything—so I built an entire cognitive architecture around the idea. (Cognitive architectures are general reasoning systems, normally built by teams of researchers, and building even a small one is part of the reason my PhD thesis took ten years, but I digress.) My cognitive architecture was called context sensitive asynchronous memory (CSAM), and it automatically collected context while the system was thinking, fed it into the context-directed spreading activation system, and incorporated dynamically remembered information into its ongoing thought processes using patch programs called integration mechanisms.
CSAM wasn’t just an idea: I built it out into a computer program called Nicole, and even published a workshop paper on it in 1997 called “Can Your Architecture Do This? A Proposal for Impasse-Driven Asynchronous Memory Retrieval and Integration.” But to get a PhD in artificial intelligence, you need more than a clever idea you’ve written up in a paper or implemented in a computer program. You need to use the program you’ve written to answer a scientific question. You need to show that your system works in the domains you claim it works in, that it can solve the problems that you claim it can solve, and that it’s better than other approaches, if other approaches exist.
So I tested Nicole on computer planning systems and showed that integration mechanisms worked. Then I and a colleague tested Nicole on a natural language understanding program and showed that memory retrieval worked. But the most important part was showing that CDSA, the heart of the theory, didn’t just work, but was better than the alternatives. I did a detailed analysis of the theory of CDSA and showed it was better than traditional spreading activation in several ways—but that rightly wasn’t enough for my committee. They wanted an example. There were alternatives to my approach, and they wanted to see that my approach was better than the alternatives for real problems.
So I turned Nicole into an information retrieval system called IRIA—the Information Retrieval Intelligent Assistant. By this time, the dot-com boom was in full swing, and my thesis advisor invited me and another graduate student to join him starting a company called Enkia. We tried many different concepts to start with, but the further we went, the more IRIA seemed to have legs. We showed she could recommend useful information to people while browsing the Internet. We showed several people could use her at the same time and get useful feedback. And critically, we showed that by using context-directed spreading activation, IRIA could retrieve better information faster than traditional spreading activation approaches.
The first publication on IRIA came out in 2000, shortly before I got my PhD thesis, and at the company things were going gangbusters. We found customers for the idea, my more experienced colleagues and I turned the IRIA program from a typical graduate student mess into a more disciplined and efficient system called the Enkion, a process we documented in a paper in early 2001. We even launched a search site called Search Orbit—and then the whole dot-com disaster happened, and the company essentially imploded. Actually, that’s not fair: the company continued for many years after I left—but I essentially imploded, and if you want to know more about that, read “Approaching 33, as Seen from 44.”
Regardless, the upshot is that I didn’t follow up on my thesis work after I finished my PhD. That happens to a lot of PhD students, but for me in particular I felt that it would have been betraying the trust of my colleagues to go publish a sequence of papers on the innards of a program they were trying to use to run their business. Eventually, they moved on to new software, but by that time, so had I.
Fast forward to 2012, and while researching an unrelated problem for The Search Engine That Starts With A G, I came across the 2006 paper “Recommending in context: A spreading activation model that is independent of the type of recommender system and its contents” by Alexander Kovács and Haruki Ueno. At Enkia, we’d thought of doing recommender systems on top of the Enkion, and had even started to build a prototype for Emory University, but the idea never took off and we never generated any publications, so at first, I was pleased to see someone doing spreading activation work in recommender systems.
Then I was unnerved to see that this approach also involved spreading activation, over a typed network, with nodes representing the types of links, and activation in the type nodes changing the way activation propagated over the links. Then I was unsettled to see that my work, which is based on a similar idea and predates their publication by almost a decade, was not cited in the paper. Then I was actually disturbed when I read: “The details of spreading activation networks in the literature differ considerably. However, they’re all equal with respect to how they handle context … context nodes do not modulate links at all…” If you were to take that at face value, the work that I did over ten years of my life—work which produced four papers, a PhD thesis, and at one point helped employ thirty people—did not exist.
Now, I was also surprised by some spooky similarities between their systems and mine—their system is built on a context-directed spreading activation model, mine is a context-directed spreading activation model, theirs is called CASAN, mine is embedded in a system called CSAM—but as far as I can see there’s NO evidence that their work was derivative of mine. As Chris Atkinson said to a friend of mine (paraphrased): “The great beam of intelligence is more like a shotgun: good ideas land on lots of people all over the world—not just on you.”
In fact, I’d argue that their work is a real advance to the field. Their model is similar, not identical, and their mathematical formalism uses more contemporary matrix algebra, making the relationship to related approaches like Page Rank more clear (see Google Page Rank and Beyond). Plus, they apparently got their approach to work on recommender systems, which we did not; IRIA did more straight up recommendation of information in traditional information retrieval, which is a similar but not identical problem.
So Kovács and Ueno’s “Recommending in Context” paper is a great paper and you should read it if you’re into this kind of stuff. But, to set the record straight, and maybe to be a little bit petty, there are a number of spreading activation systems that do use context to modulate links in the network … most notably mine.
-the Centaur
Pictured: a tiny chunk of the WordNet online dictionary, which I’m using as a proxy of a semantic network. Data processing by me in Python, graph representation by the GraphViz suite’s dot program, and postprocessing by me in Adobe Photoshop.
Let me completely up front about my motivation for writing this post: recently, I came across a paper which was similar to the work in my PhD thesis, but applied to a different area. The paper didn’t cite my work – in fact, its survey of related work in the area seemed to indicate that no prior work along the lines of mine existed – and when I alerted the authors to the omission, they informed me they’d cited all relevant work, and claimed “my obscure dissertation probably wasn’t relevant.” Clearly, I haven’t done a good enough job articulating or promoting my work, so I thought I should take a moment to explain what I did for my doctoral dissertation.
My research improved computer memory by modeling it after human memory. People remember different things in different contexts based on how different pieces of information are connected to one another. Even a word as simple as ‘ford’ can call different things to mind depending on whether you’ve bought a popular brand of car, watched the credits of an Indiana Jones movie, or tried to cross the shallow part of a river. Based on that human phenomenon, I built a memory retrieval engine that used context to remember relevant things more quickly.
My approach was based on a technique I called context directed spreading activation, which I argued was an advance over so-called “traditional” spreading activation. Spreading activation is a technique for finding information in a kind of computer memory called semantic networks, which model relationships in the human mind. A semantic network represents knowledge as a graph, with concepts as nodes and relationships between concepts as links, and traditional spreading activation finds information in that network by starting with a set of “query” nodes and propagating “activation” out on the links, like current in an electric circuit. The current that hits each node in the network determines how highly ranked the node is for a query. (If you understand circuits and spreading activation, and this description caused you to catch on fire, my apologies. I’ll be more precise in future blogposts. Roll with it).
The problem is, as semantic networks grow large, there’s a heck of a lot of activation to propagate. My approach, context directed spreading activation (CDSA), cuts this cost dramatically by making activation propagate over fewer types of links. In CDSA, each link has a type, each type has a node, and activation propagates only over links whose nodes are active (to a very rough first approximation, although in my evaluations I tested about every variant of this under the sun). Propagating over active links isn’t just cheaper than spreading activation over every link; it’s smarter: the same “query” nodes can activate different parts of the network, depending on which “context” nodes are active. So, if you design your network right, Harrison Ford is never going to occur to you if you’ve been thinking about cars.
I was a typical graduate student, and I thought my approach was so good, it was good for everything—so I built an entire cognitive architecture around the idea. (Cognitive architectures are general reasoning systems, normally built by teams of researchers, and building even a small one is part of the reason my PhD thesis took ten years, but I digress.) My cognitive architecture was called context sensitive asynchronous memory (CSAM), and it automatically collected context while the system was thinking, fed it into the context-directed spreading activation system, and incorporated dynamically remembered information into its ongoing thought processes using patch programs called integration mechanisms.
CSAM wasn’t just an idea: I built it out into a computer program called Nicole, and even published a workshop paper on it in 1997 called “Can Your Architecture Do This? A Proposal for Impasse-Driven Asynchronous Memory Retrieval and Integration.” But to get a PhD in artificial intelligence, you need more than a clever idea you’ve written up in a paper or implemented in a computer program. You need to use the program you’ve written to answer a scientific question. You need to show that your system works in the domains you claim it works in, that it can solve the problems that you claim it can solve, and that it’s better than other approaches, if other approaches exist.
So I tested Nicole on computer planning systems and showed that integration mechanisms worked. Then I and a colleague tested Nicole on a natural language understanding program and showed that memory retrieval worked. But the most important part was showing that CDSA, the heart of the theory, didn’t just work, but was better than the alternatives. I did a detailed analysis of the theory of CDSA and showed it was better than traditional spreading activation in several ways—but that rightly wasn’t enough for my committee. They wanted an example. There were alternatives to my approach, and they wanted to see that my approach was better than the alternatives for real problems.
So I turned Nicole into an information retrieval system called IRIA—the Information Retrieval Intelligent Assistant. By this time, the dot-com boom was in full swing, and my thesis advisor invited me and another graduate student to join him starting a company called Enkia. We tried many different concepts to start with, but the further we went, the more IRIA seemed to have legs. We showed she could recommend useful information to people while browsing the Internet. We showed several people could use her at the same time and get useful feedback. And critically, we showed that by using context-directed spreading activation, IRIA could retrieve better information faster than traditional spreading activation approaches.
The first publication on IRIA came out in 2000, shortly before I got my PhD thesis, and at the company things were going gangbusters. We found customers for the idea, my more experienced colleagues and I turned the IRIA program from a typical graduate student mess into a more disciplined and efficient system called the Enkion, a process we documented in a paper in early 2001. We even launched a search site called Search Orbit—and then the whole dot-com disaster happened, and the company essentially imploded. Actually, that’s not fair: the company continued for many years after I left—but I essentially imploded, and if you want to know more about that, read “Approaching 33, as Seen from 44.”
Regardless, the upshot is that I didn’t follow up on my thesis work after I finished my PhD. That happens to a lot of PhD students, but for me in particular I felt that it would have been betraying the trust of my colleagues to go publish a sequence of papers on the innards of a program they were trying to use to run their business. Eventually, they moved on to new software, but by that time, so had I.
Fast forward to 2012, and while researching an unrelated problem for The Search Engine That Starts With A G, I came across the 2006 paper “Recommending in context: A spreading activation model that is independent of the type of recommender system and its contents” by Alexander Kovács and Haruki Ueno. At Enkia, we’d thought of doing recommender systems on top of the Enkion, and had even started to build a prototype for Emory University, but the idea never took off and we never generated any publications, so at first, I was pleased to see someone doing spreading activation work in recommender systems.
Then I was unnerved to see that this approach also involved spreading activation, over a typed network, with nodes representing the types of links, and activation in the type nodes changing the way activation propagated over the links. Then I was unsettled to see that my work, which is based on a similar idea and predates their publication by almost a decade, was not cited in the paper. Then I was actually disturbed when I read: “The details of spreading activation networks in the literature differ considerably. However, they’re all equal with respect to how they handle context … context nodes do not modulate links at all…” If you were to take that at face value, the work that I did over ten years of my life—work which produced four papers, a PhD thesis, and at one point helped employ thirty people—did not exist.
Now, I was also surprised by some spooky similarities between their systems and mine—their system is built on a context-directed spreading activation model, mine is a context-directed spreading activation model, theirs is called CASAN, mine is embedded in a system called CSAM—but as far as I can see there’s NO evidence that their work was derivative of mine. As Chris Atkinson said to a friend of mine (paraphrased): “The great beam of intelligence is more like a shotgun: good ideas land on lots of people all over the world—not just on you.”
In fact, I’d argue that their work is a real advance to the field. Their model is similar, not identical, and their mathematical formalism uses more contemporary matrix algebra, making the relationship to related approaches like Page Rank more clear (see Google Page Rank and Beyond). Plus, they apparently got their approach to work on recommender systems, which we did not; IRIA did more straight up recommendation of information in traditional information retrieval, which is a similar but not identical problem.
So Kovács and Ueno’s “Recommending in Context” paper is a great paper and you should read it if you’re into this kind of stuff. But, to set the record straight, and maybe to be a little bit petty, there are a number of spreading activation systems that do use context to modulate links in the network … most notably mine.
-the Centaur
Pictured: a tiny chunk of the WordNet online dictionary, which I’m using as a proxy of a semantic network. Data processing by me in Python, graph representation by the GraphViz suite’s dot program, and postprocessing by me in Adobe Photoshop. 
So, after my scare over almost losing 150+ files on Google Drive, I've made some progress on integrating Google Drive and Dropbox using cloudHQ. The reason it wasn't completely seamless is that I use both Google Drive and Dropbox on my primary personal laptop, and cannot afford to have two copies of all files on this one machine. The other half of this problem is that if you only set up partial sync of certain folders, then any new files added to the top folder of Google Drive or Dropbox won't get replicated - and believe it or not, that's already happened to me. So I need a "reliable scheme" I can count on.
The solution? Set up a master folder on Google Drive called "Replicated", in which everything that I want to keep - all my Google Docs, in particular - will get copied to a folder of the same name called "Replicated" in Dropbox. For good measure, set up another replication pair for the Shared folder of Google Drive. The remaining files, all the Pictures I've stored because of Google Drive's great bang for the buck storage deal, don't need to be replicated here.
The reason this works is that if you obey the simple anal-retentive policy of creating all your Google Docs within a named folder, and you put all your named folders under Replicated, then they all automatically get copied to Dropbox as documents. I've even seen it in action, as I edit Google Docs and Dropbox informs me that new copies of documents in Microsoft Word .docx format are appearing in my drive. Success!
At last, I've found a way to reliably use Google Drive cloud. Google doesn't always support the features you want, or the patterns of usage that you want, but they're deeply committed to open APIs, to data liberation, and to the creation of third party applications that enable you to fill the gaps in Google's services so that you aren't locked in to one solution.
Breaking News: Google Reader canceled. G*d dammit, Google…
Next up: after my scare of losing Google Reader, a report on my progress using The Old Reader to rescue my feeds...
-the Centaur
Pictured: A table candle at Cascal's in Mountain View, Ca...

Ok, the above is a rescue cat, but the point remains. In an earlier post I understandably got a bit miffed when moving a folder within Google Drive - an operation I've done before, many times - mysteriously deleted over a hundred and fifty files. I was able to rescue them, but I felt like I couldn't trust Google Drive - a feeling confirmed when the very next time I used it to collect some quick notes, the application crashed.
But I love the workflow of Google Drive - the home page of Google Drive can show you, very very quickly, either your hierarchy of folders, your recently accessed files, or a search of all your files, and once you've found a file it appears far quicker than most normal applications like Microsoft Word, Microsoft Excel, or Photoshop. Word, Excel and Photoshop kick Google Drive's ass on specialized uses, but many documents don't need that, and Google Drive is a great alternative.
But what about files disappearing? A non starter. However, there are ways around that problem.
Google Drive of course has the ability to export files. You can even export an entire directory in this fashion. If you really want to get serious, you can use Google Takeout, a data migration tool by Google which enables you to export all your Google Drive data, part of Google's Data Liberation Front.
But all those rely on one time manual operations. I want something that works automatically, so for my money it's the Google Drive API that really comes to the rescue. That enables developers to create applications like cloudHQ, which syncs between Google Drive, Dropbox and several other services. I've tried out cloudHQ experimentally and it works on a single folder.
Next I'm going to try it on a larger scale, though it will require a little re-sorting of how I've got Dropbox and Google Drive working. Most likely, I'm going to need to either uninstall Google Drive from my primary computer and sync all its files into Dropbox by CloudHQ, or else manually unsyc certain folders so I don't get double-storage on this machine.
Regardless, there is a silver lining. Now let's see if it's also a silver bullet.
-the Centaur
Pictured: Me holding Loki, our outdoor rescue cat. He's large marge, let me tell you.
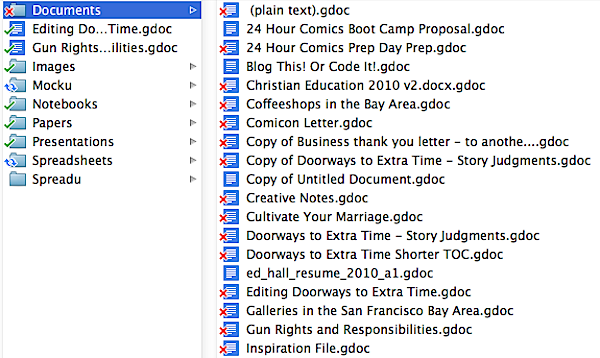
Recently I was doing some task and needed to track down some information. I couldn't find the document I wanted at first in my Google Drive, but once I did, I realized I had several documents, all on the same topic, so I did with Google Drive the same thing I'd done before on Google Drive: I went to the Google Drive folder and reorganized the files.
Big mistake.
Quickly red "x's" started appearing in my folders. More and more "unsyncable" files started showing up in the Google Drive status list. And then a status message popped up: "The files you have deleted are now in Google Drive's Trash."
Uh-oh.
Understand: I had deleted no files or folders. I simply moved them around - and I've done this before. A lot. On Google Drive, not just Dropbox. But something apparently happened in the sync, and Google Drive thought I'd deleted the folders.
So it trashed all those files.
Understand, Google Drive "documents" on your hard drive aren't "documents"; they're little text files with pointers to a location in Google Drive, like this (where UNREADABLE_IDENTIFIER is a string of alphanumeric gobbledegook):
{"url": "https://docs.google.com/document/d/UNREADABLE_IDENTIFIER/edit", "resource_id": "document:UNREADABLE_IDENTIFIER"}
This pathetic little bit of nonsense is all I would have had left of a 200 word start to an essay - if I hadn't acted quickly. I started to look online, and found this alarming bit of information:
https://support.google.com/drive/bin/answer.py?hl=en&answer=2375102Declutter your Google Drive by removing unwanted and outdated files, folders, and Google Docs from your Google Drive. Anything that you own and remove from Google Drive will be in the trash until you permanently delete or restore them.
Moving Google Docs files out of your Google Drive folder will cause their counterpart files on the web to be moved to the trash. If you then purge the trash, those files will become permanently inaccessible. Because the Docs files in your Drive folder are essentially links to files that exist online, moving these files back into your Drive folder after purging the trash online will not restore the files, as their online counterparts will have been deleted.
OMG! The contents of my documents may be lost forever if I purge the trash. But it gets worse...
http://support.google.com/drive/bin/answer.py?hl=en&answer=2494934If something in Google Drive is moved to the trash, you'll see a warning and you may lose access to it at any time. Read one of the following sections to learn how to restore it to your Google Drive from the trash. When you restore something, it'll be recovered in Google Drive on the web, to the Google Drive folder on your computer, and to your mobile devices.
If the item is in a folder, you’ll need to restore the entire folder to recover any individual items inside of it.
So I quickly returned to Google Drive. Everything you see above with a little red X was gone, all those files and 150 more. I hunted down the Trash (which was harder than you might think, as there was some persistent search in my Google Drive window that was removing the Trash folder from my view) and restored EVERYTHING that I had never deleted in the first place.
Now, this shouldn't have been a surprise. I always knew this could happen, ever since I gladly installed Google Drive on on my Mac in the hope that it would data liberate the Google Documents I had, only to find in my horror that Google Drive wasn't a syncing system, like Dropbox, but a cloud system, which is useless.
In case anyone misses the point: If you use Google Drive to store documents and also have the Google Drive client stored on a machine, Google Drive can get tricked into thinking you've deleted files, at which point it will move them to the Trash, at which point, unlike things you've deliberately trashed, it can delete them at any time - and you'll never get them back.
After some thought, I'm calling a hard stop on all use of Google Documents, except those I'm using to collaborate with others, where the collaboration features of the Google Doc outweigh the potential of risk. I can always save those files to a hard backup of a Word document or an Excel spreadsheet.
But I work for a living as a writer. And I can't work with a system that can arbitrarily trash hundreds of files and thousands upon thousands of words of documents with no hope of recovery just because I moved a folder … correctly.
Like Ecto, I have to rethink my use of these online tools - rethink them in a way that ensures that for every significant thing that I use in some convenient online system, I have a saved copy in an archivable backup.
More updates as I develop a new system.
-the Centaur